Data Engineering Weekly #240
来源: Data Engineering Weekly

The data platform playbook everyone’s using
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Kyle Weller: Apache Iceberg™ vs Delta Lake vs Apache Hudi™ - Feature Comparison Deep Dive
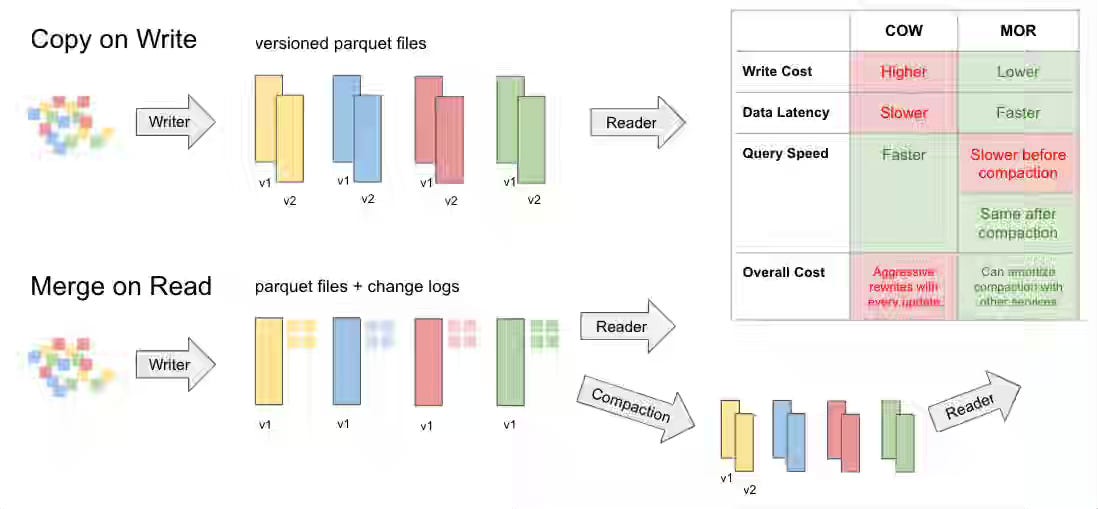
The industry has quickly moved on from the Great Lakehouse debate and is rapidly gaining adoption. The blog from Onehouse revisits the current state of the Lakehouse systems as features like real-time mutation capabilities and multi-table/multi-query transactions become more mainstream.
Anthropic: Effective context engineering for AI agents
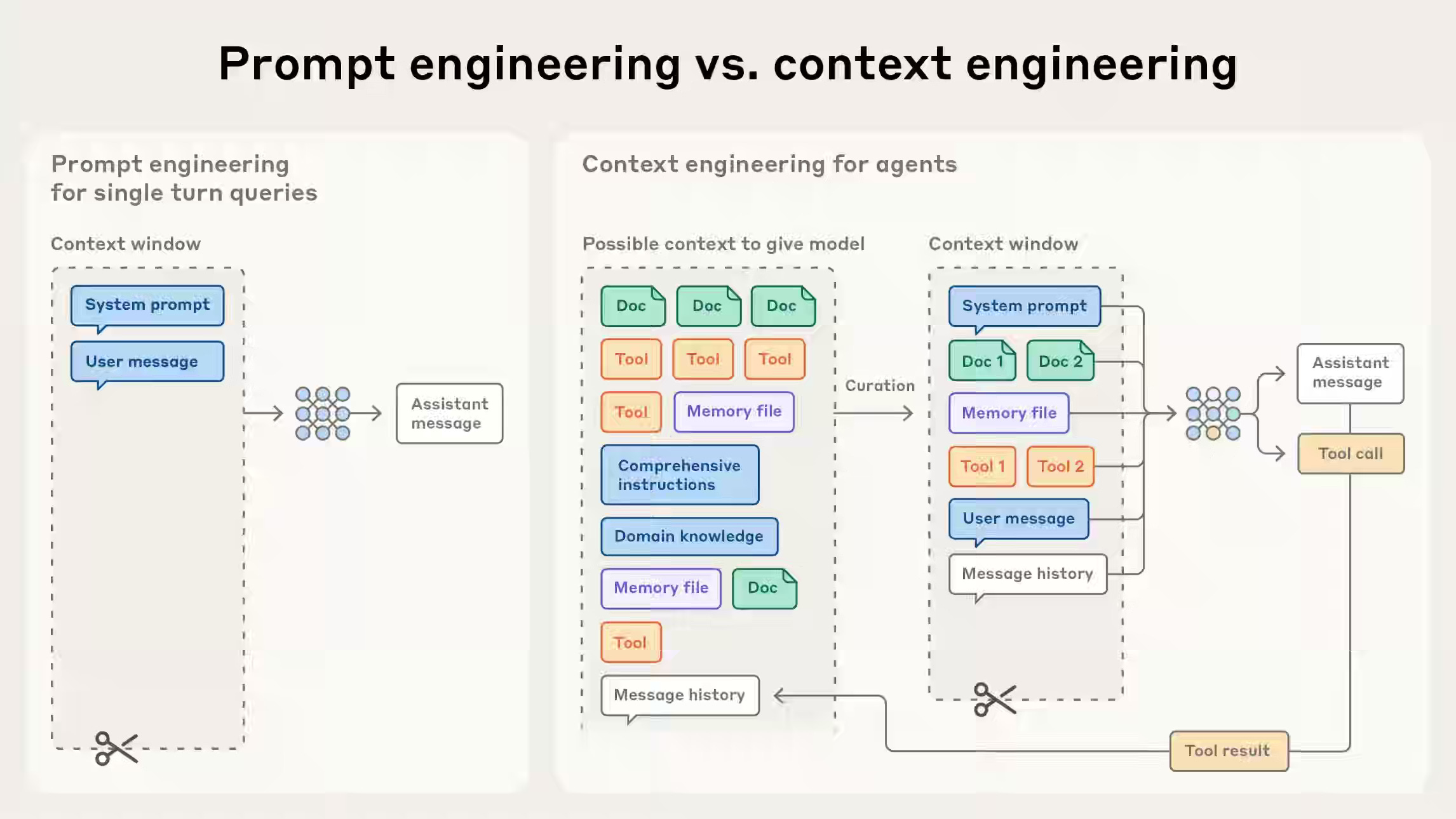
As AI agents evolve beyond simple prompt-based systems, managing the limited “attention budget” of large language models has become a central engineering challenge. Anthropic writes about context engineering—a discipline focused on curating, compressing, and dynamically retrieving only the most relevant tokens during inference to sustain coherent, efficient, and long-horizon agent behavior. By combining strategies such as compaction, structured note-taking, and multi-agent architectures, the context engineering approach enables agents to act more autonomously while maintaining focus and reliability across extended tasks.
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Uber: How Uber Standardized Mobile Analytics for Cross-Platform Insights
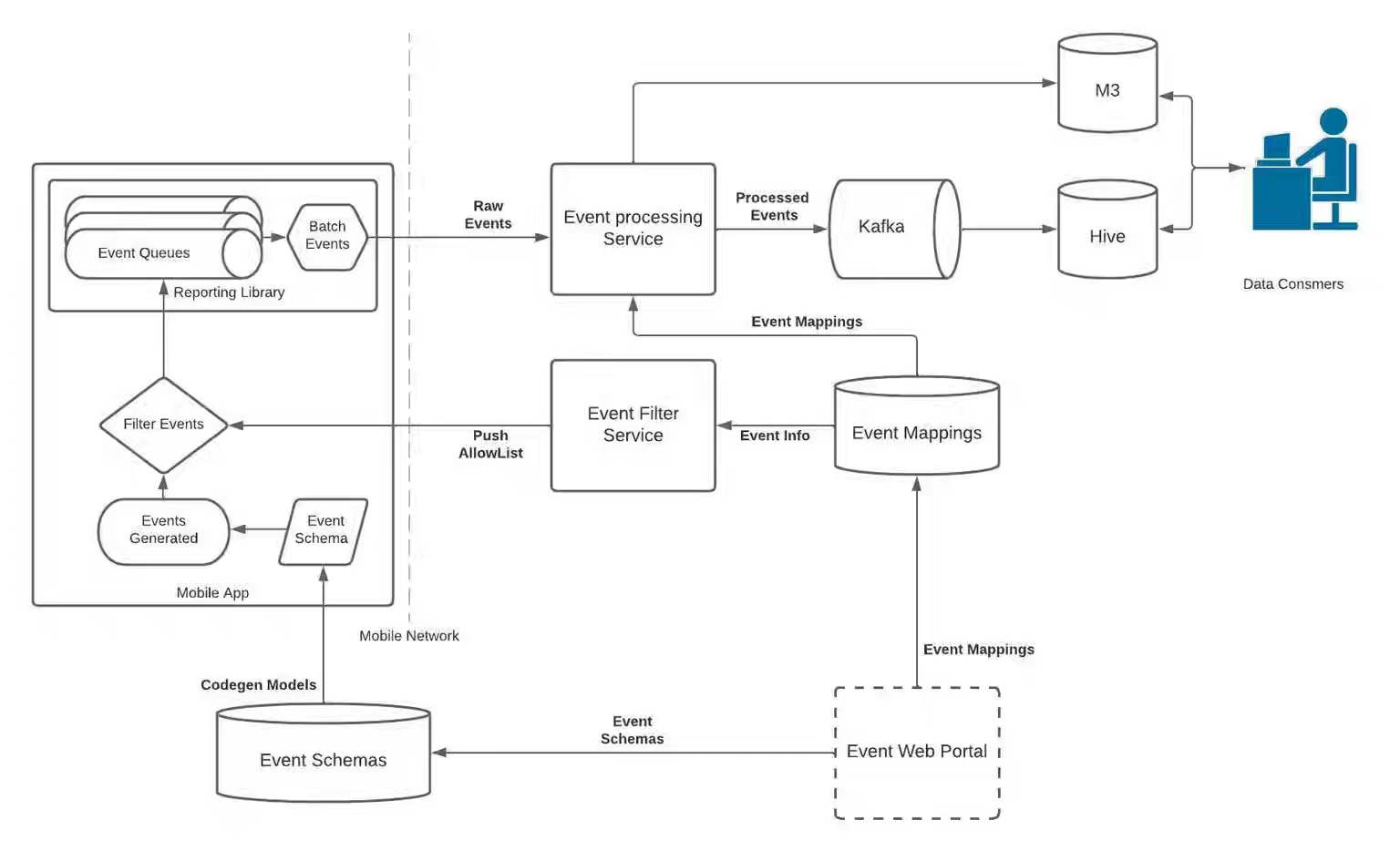
Inconsistent event definitions and ad-hoc instrumentation led to fragmented analytics data and high developer overhead. Uber’s Mobile Analytics team writes about rebuilding its analytics platform with standardized event types, centralized metadata collection, and a unified instrumentation framework that automatically emits consistent tap, impression, and scroll events across platforms. This standardization reduced redundant code, improved cross-platform data quality and reliability, and laid the foundation for a component-based analytics model that simplifies event naming and lifecycle management at scale.
https://www.uber.com/en-IN/blog/how-uber-standardized-mobile-analytics/
Sponsored: From Chaos to Real-Time Insights for Manufacturing

In this Deep Dive, Supplyco’s CTO Claudia Richoux will reveal how they built a pipeline in Dagster that processes 100,000+ data streams in real time — while ensuring 99.99% uptime. You’ll see their DAG architecture in action, learn how they built observability into every layer, and how they treat “data as code” to ship fast and smart.
Netflix: 100X Faster: How We Supercharged Netflix Maestro’s Workflow Engine
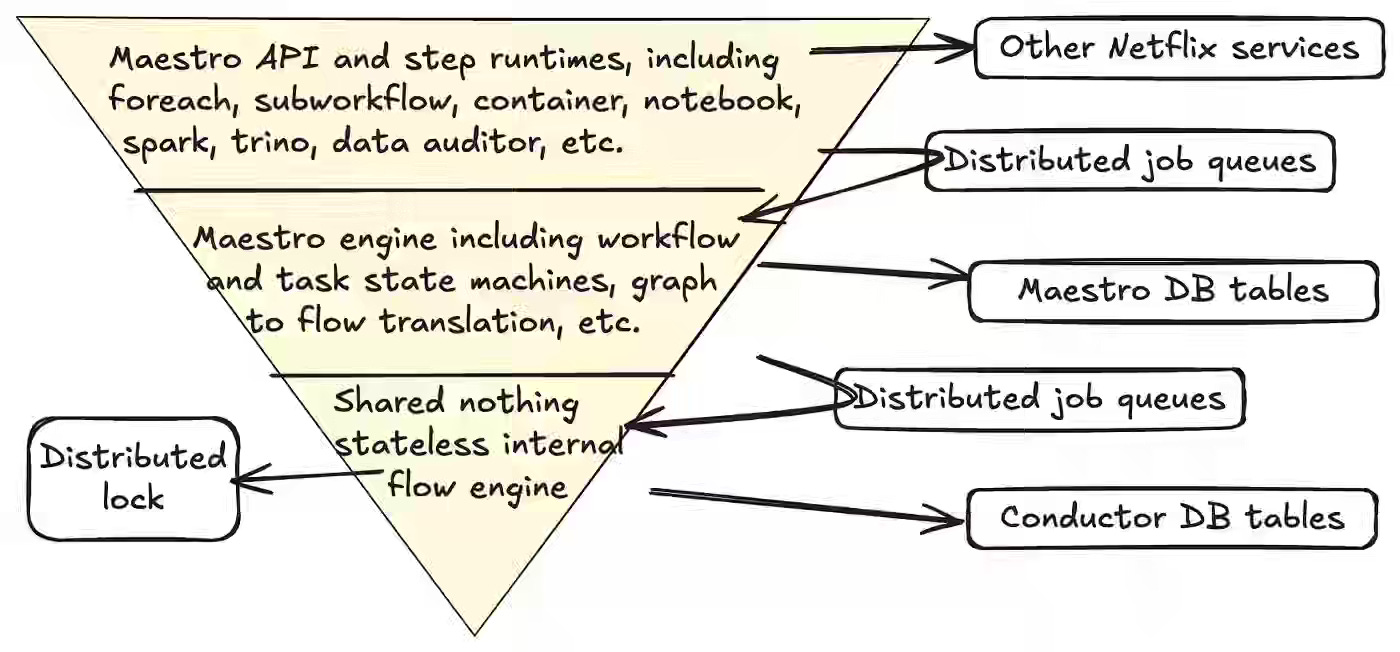
Large-scale workflow orchestrators often hit scalability goals but still impose multi-second engine overheads that slow iteration and block emerging low-latency use cases. Netflix writes about rebuilding Maestro’s core with a lightweight, stateful actor model using Java virtual threads, in-memory state, internal exactly-once queues, and group-based partitioning. The redesign delivers ~100× faster execution (step launch 5s→50ms; workflow start 200ms→50ms), smoothly migrated ~60k workflows (>1M tasks/day), and cut operational load (≈90% fewer DB queries, ~40 TB of legacy tables removed).
Alibaba: Building a Unified Lakehouse for Large-Scale Recommendation Systems with Apache Paimon at TikTok
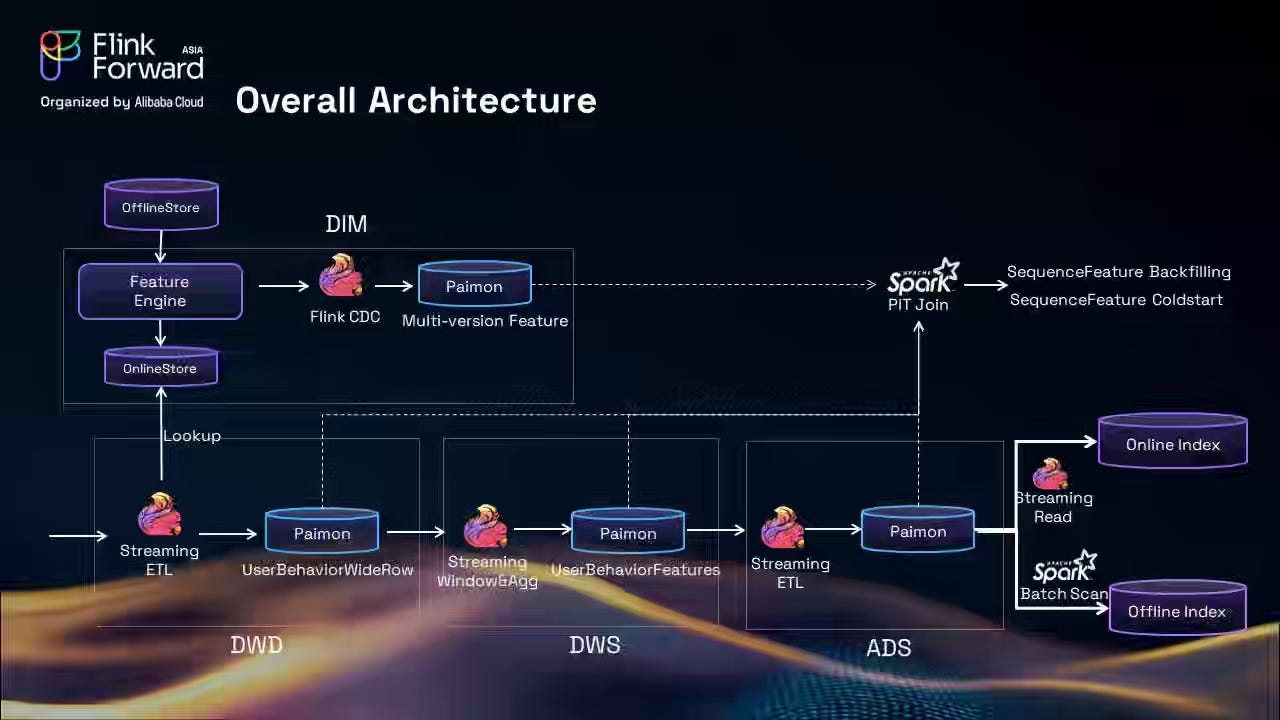
TikTok writes about the challenges associated with fragmented feature pipelines, complex Lambda architectures, and multi-day latency in processing user behavior data. The blog discusses rebuilding its recommendation data foundation as a unified Lakehouse on Apache Paimon, integrating Flink and Spark for exactly-once, stream-batch, and unified processing, as well as point-in-time joins.
Sponsored: Join the industry’s first survey on data platform migrations.

Most data teams have faced code or logic migrations—rewriting SQL, translating stored procedures, or replatforming ETL workloads—and they’re rarely straightforward. But there’s no clear benchmark for how long these projects take, what they cost, or how teams actually validate success.
Datafold is running a 5-minute survey to collect ground truth from practitioners on timelines, validation, budgets, and how AI is introducing new ways of tackling code translation and validation. Qualified Data Engineering Weekly subscribers (with a valid work email) get a $25 gift card, and all participants receive early access to the results.
Netflix: Building a Resilient Data Platform with Write-Ahead Log at Netflix
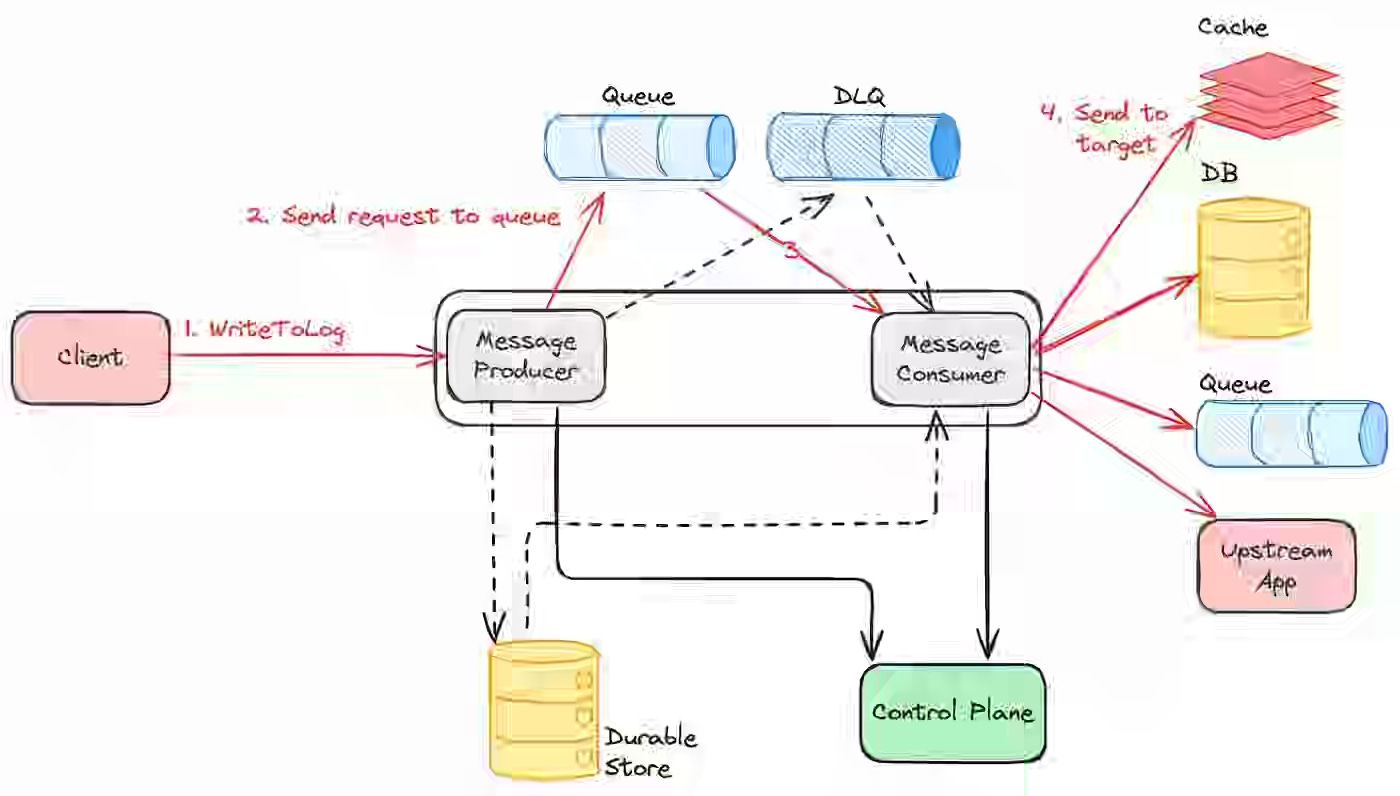
Ensuring data consistency and durability across Netflix’s massive, multi-datastore ecosystem proved challenging as teams battled data corruption, replication gaps, and unreliable retries. Netflix describes building a generic Write-Ahead Log (WAL) abstraction. This pluggable, distributed system captures and replays mutations with strong durability guarantees across storage engines, including Cassandra, EVCache, and Kafka.
Dropbox: A practical blueprint for evaluating conversational AI at scale
Building reliable LLM products requires as much rigor in evaluation as in model design. Dropbox shares how it built a structured, automated evaluation pipeline for Dropbox Dash, treating prompt and model changes like production code—tested, versioned, and gated by LLM-based judges and real-world datasets. By combining curated benchmarks, automated regression gates, live-traffic scoring, and continuous feedback loops, Dropbox turned evaluation into an engineering discipline that catches regressions early, enforces factual accuracy, and drives faster, safer iteration on AI features.
https://dropbox.tech/machine-learning/practical-blueprint-evaluating-conversational-ai-at-scale-dash
Hugging Face: Introducing RTEB: A New Standard for Retrieval Evaluation
Accurately measuring how well embedding models retrieve unseen information has become a critical gap in evaluating modern AI systems. Hugging Face writes about the Retrieval Embedding Benchmark (RTEB) - a new standard that combines open and private datasets to assess true generalization and prevent “teaching to the test.” Designed for real-world, multilingual, and domain-specific use cases across text retrieval.
https://huggingface.co/blog/rteb
DuckDB: Redesigning DuckDB’s Sort, Again
Handling large, out-of-memory sorts efficiently has long been a performance bottleneck for analytical databases, such as DuckDB. In version 1.4.0, DuckDB introduces a fully redesigned sort engine that integrates its new spillable page layout, utilizes normalized sort keys, employs adaptive hybrid algorithms, and features a parallel k-way merge for fine-grained scalability. The result is up to 10 times faster performance on pre-sorted data, 3 times faster wide-table sorts, and significantly improved parallel scaling, setting a new foundation for future sort-based joins and window functions.
https://duckdb.org/2025/09/24/sorting-again.html
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
