数据工程周报 #264
来源: Data Engineering Weekly

How data teams are solving multi-tenancy
As data teams grow and serve multiple teams, clients, or business units from a shared platform, maintaining isolation and velocity without sacrificing either becomes a defining architectural challenge.
In this Deep Dive, Dagster Labs and Brooklyn Data Co. will cover the patterns, trade-offs, and real-world implementations behind multi-tenant data platforms built on Dagster. Attendees will leave this session with practical guidance they can take back to their own teams.
Editorial Note: Help Us Make Data Engineering Weekly Better
We’re working to make Data Engineering Weekly more useful, more relevant, and more worth your time every Sunday. If you have 2 minutes, please share your feedback through this short survey. Your input will directly shape what we cover, how we write, and where we improve next.
https://forms.gle/cgeww7czFAVBiVmV7
Meta: Inside Meta’s Home-Grown AI Analytics Agent
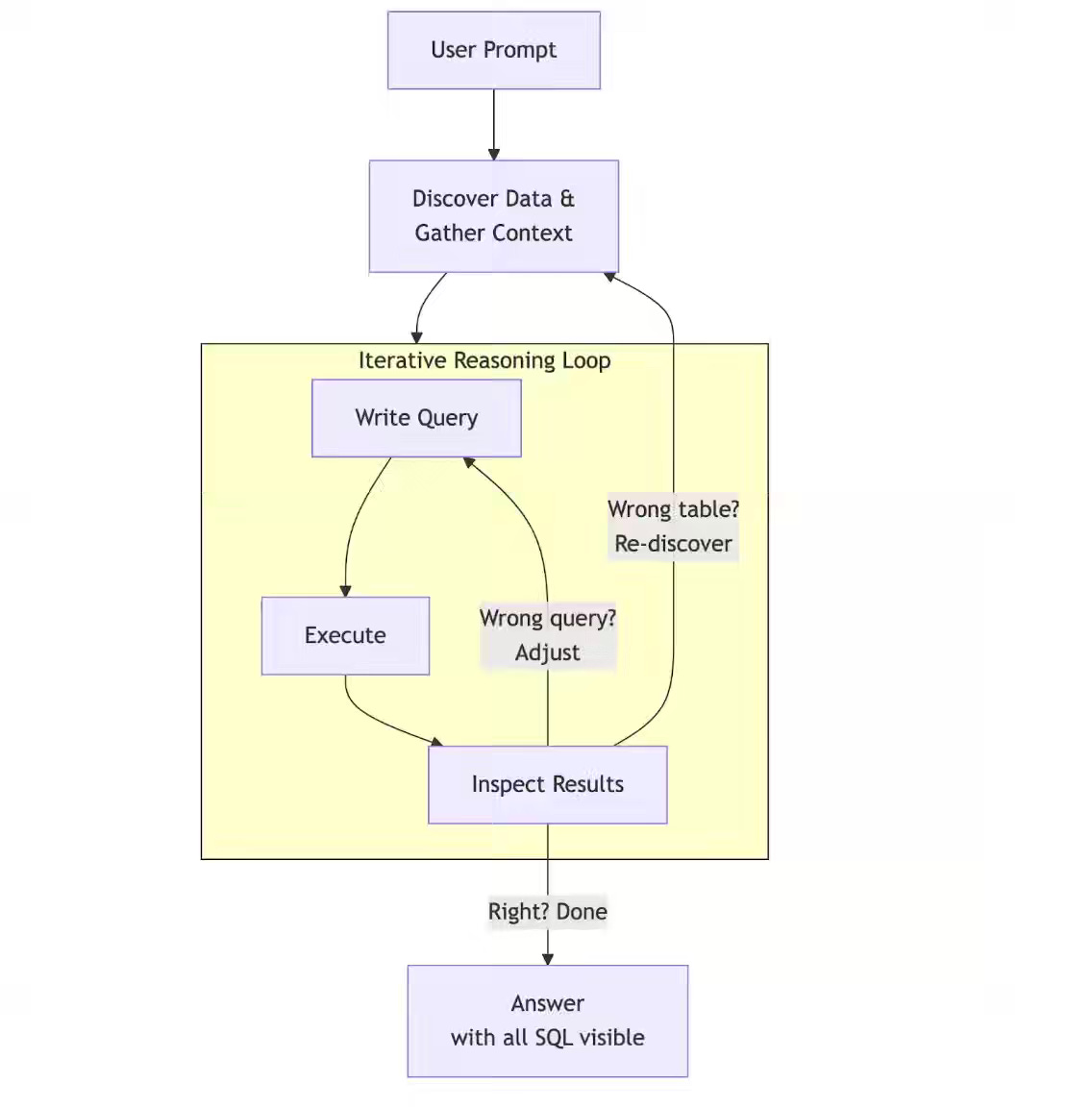
Routine analytical queries dominate enterprise data science workloads, yet agents fail as warehouse scale grows without a bounded, structured context. Meta Platforms seeds per-user memory from historical query logs and organizes domain knowledge into cookbooks, recipes, and ingredients that encode validated analyst logic. This approach drives 77% weekly adoption within six months as community-authored recipes expand coverage across domains
https://medium.com/@AnalyticsAtMeta/inside-metas-home-grown-ai-analytics-agent-4ea6779acfb3
Michel Tricot: Beyond ETL - The Case for Context
Agentic data infrastructure exposes a meaning gap that traditional ETL never addressed, as autonomous agents propagate poor context across queries at scale. The author validates the ECL framework through real-world failures and reframes the Context Store as a materialized view that pre-replicates SaaS data into versioned semantic structures for agent consumption. Existing data engineering primitives—incremental replication, schema normalization, and tenant isolation—support this model, shifting the data engineer’s role from data movement to context architecture.
https://agentblueprint.substack.com/p/beyond-etl-the-case-for-context
Chris Gambill: Medallion Architecture Isn’t As New As You Think
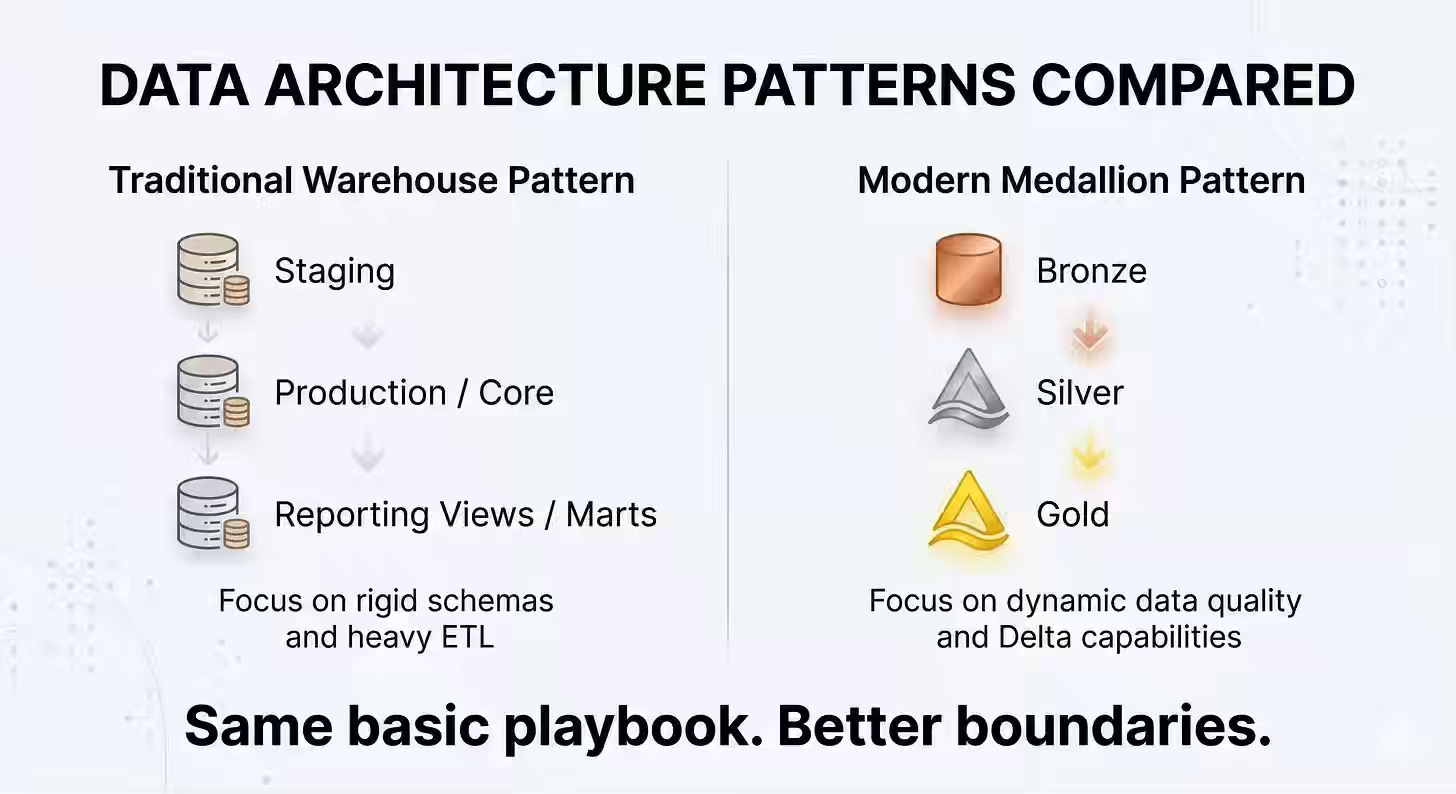
AI tools amplify data-quality failures at scale when pipelines lack clear boundaries among the raw capture, transformation, and business-consumption layers. The author reframes Medallion Architecture as a disciplined evolution of staging and reporting models: Bronze preserves raw audit trails, Silver enforces schema contracts, and Gold delivers business-ready KPIs. This separation provides a reliable context for AI systems and reduces the downstream cost of bad data beyond incremental storage overhead.
https://gambilldataengineering.substack.com/p/medallion-architecture-isnt-as-new
Sponsored: The Data Platform Fundamentals Guide

Learn the fundamental concepts to build a data platform in your organization.
- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Zapier: Lessons from using the outbox pattern at scale
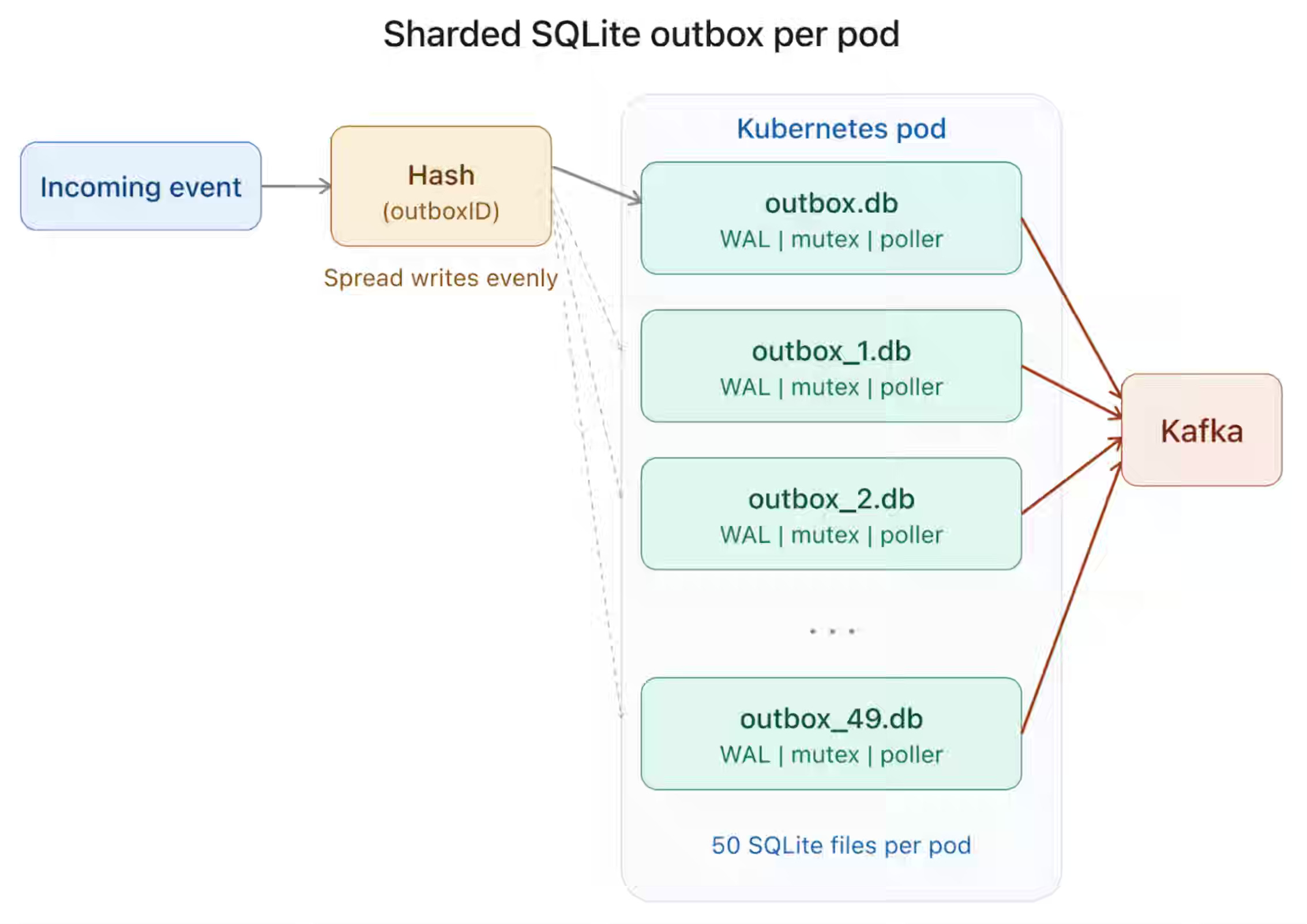
High-throughput event pipelines require durable buffering between producers and brokers to prevent data loss during failures or maintenance windows. Zapier implements a transactional outbox in its Go-based Events API using sharded SQLite on EBS-backed Kubernetes StatefulSets, with WAL mode, 50 shards per pod, and per-shard mutexes sustaining 15,000 events per second during Kafka outages. Operational limits from static sharding and StatefulSet constraints push a shift toward a sidecar pattern that writes to S3 on failure and replays via SQS.
https://zapier.com/blog/lessons-from-using-outbox-pattern-at-scale/
Lyft: Predicting Rider Conversion in Sparse Data Environments with Bayesian Trees
Sparse contextual data causes standard ML models to overfit and generate unstable predictions across long-tail combinations of location, time, and demand. Lyft models rider conversion using a Bayesian Tree that organizes context hierarchically and applies Gaussian priors with L2 regularization to balance sparse leaf signals against stable parent trends. This approach delivers localized accuracy in dense data and degrades to broader signals in sparse regions, while enforcing monotonicity constraints to ensure consistent, interpretable predictions.
LinkedIn: Building LinkedIn’s CTV Ads: Scaling professional reach to the big screen
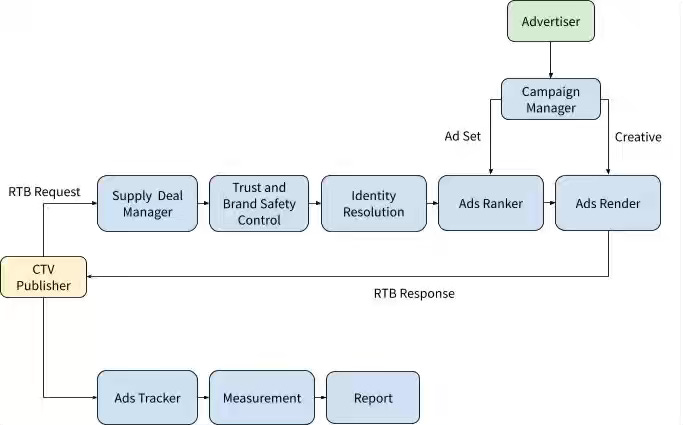
B2B advertisers struggle to reach professional audiences on connected TV while maintaining the targeting precision and measurement fidelity of digital environments. LinkedIn extends its identity graph to CTV through private marketplace supply, cross-device household mapping, and transcoding pipelines that meet CBR encoding and native frame rate standards. The platform delivers 99% brand-safe inventory, achieves 11x cost efficiency over linear TV, and scales from manual deals to self-serve inventory via Campaign Manager.
https://www.linkedin.com/blog/engineering/marketing/building-linkedins-ctv-ads
Netflix: Synchronizing the Senses: Powering Multimodal Intelligence for Video Search
Video search across large productions requires unifying outputs from multiple ML models into a low-latency retrieval system that editors can query in real time. Netflix pipelines multimodal annotations through Cassandra for high-throughput ingestion, Kafka for temporal bucketing into one-second intervals, and Elasticsearch for hierarchical indexing that combines character, scene, and dialogue signals. The system enables semantic vector search via HNSW, supports match-phrase dialogue queries, and applies union–intersection logic to reconstruct scene boundaries across billions of data points.
https://netflixtechblog.com/powering-multimodal-intelligence-for-video-search-3e0020cf1202
Salesforce: Inside Informatica’s Spark-Based Data Integration Platform: Running 250K Enterprise Pipelines Daily
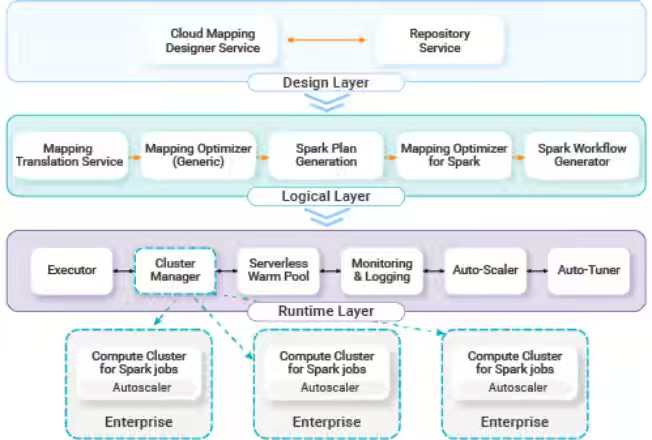
Enterprise data integration platforms struggle at the petabyte scale when single-node execution engines lack distributed compute and automated resource optimization. Informatica migrates CDI to Spark++ on Kubernetes, preserving graphical mappings while introducing row-level fault isolation, ephemeral, VPC-bound clusters, and automated FinOps tuners that optimize infrastructure and Spark parameters based on historical workloads. The distributed system supports 5,500 enterprise clients across 250,000 daily tasks, reduces infrastructure costs by 1.65x, and maintains 99.9% control plane availability.
ZeroToOne: Taming S3 Shuffle at Scale
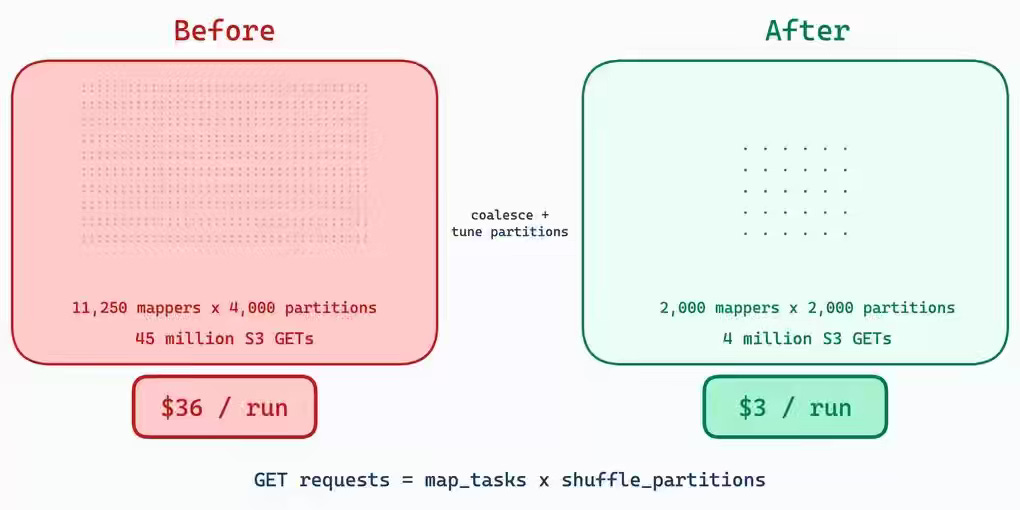
S3-based Spark shuffle suffers from quadratic scaling of GET requests, prefix throttling, and executor hangs, which drive high API costs and instability at production scale. ZeroToOne reduces shuffle costs by 95% by coalescing map tasks and expanding S3 prefixes from 10 to 500, then hardens the shuffle plugin with ConcurrentHashMap-based atomic locking and prefetch iterator timeouts to eliminate race conditions and deadlocks. These changes stabilize spot instance execution and reduce per-stage API costs from $72 to near zero in large backfill workloads.
https://blog.platform.zerotoone.ai/blog/taming-s3-shuffle-at-scale/
Radim Marek: Production query plans without production data
Just the other day, I was in a design discussion about building a routing engine for SQL query execution based on the query plan, and how to back this up in the CI pipeline to catch expensive queries earlier. It is one of the critical problems that I wish all data warehouses and Lakehouses would provide out of the box.
https://boringsql.com/posts/portable-stats/
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
