数据工程周报 #267
来源: Data Engineering Weekly
Free Course: AI-Driven Data Engineering
AI coding agents are changing how data engineers work. This Dagster University course shows how to build a production-ready ELT pipeline from prompts while learning practical patterns for reliable AI-assisted development.
This course is designed for engineers exploring agentic coding workflows and engineers who want to learn Dagster or become Dagster power users.
Monzo: A “meshy” approach to Data: Enabling 100+ teams to build Data Models
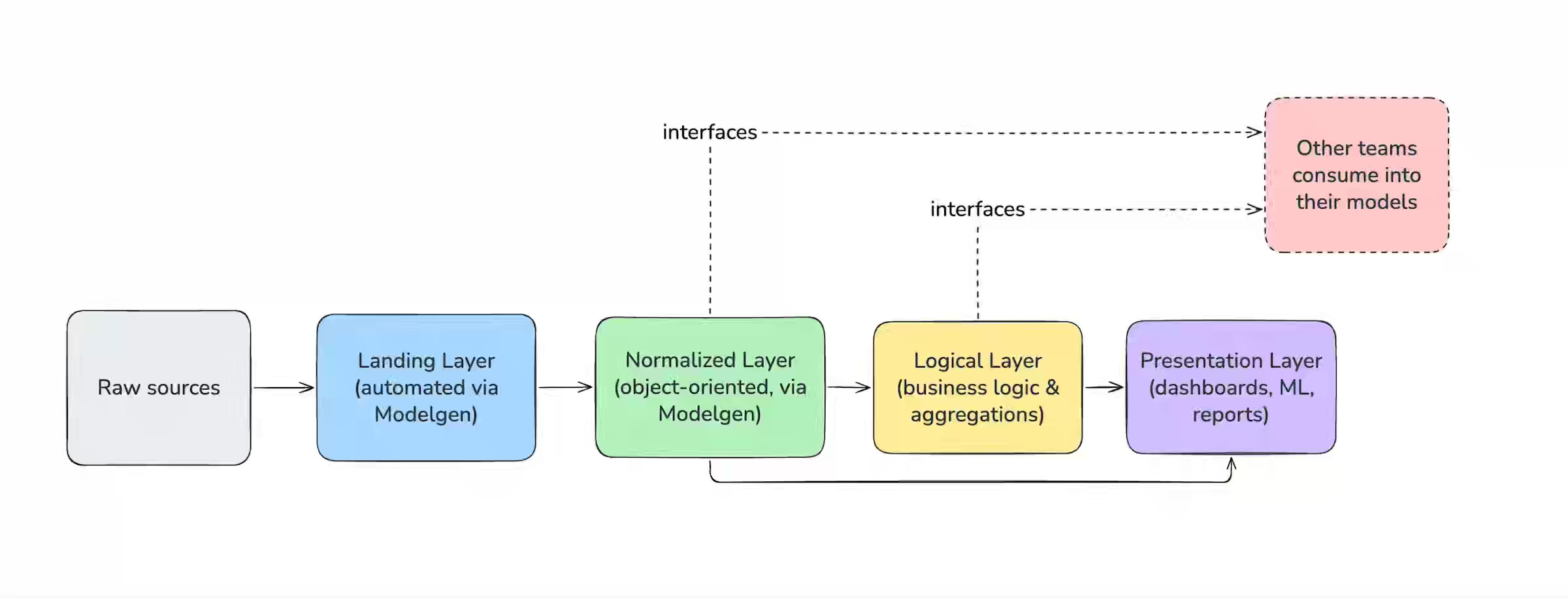
Decentralized data ownership breaks down when cross-team dependencies remain implicit and upstream schema changes silently cascade through downstream models. Monzo introduces Interfaces—explicitly declared, tested dbt models that serve as governed data contracts—stabilizing cross-domain consumption across its 12,000-model warehouse. The migration has already reduced processing costs by 40% and accelerated data landing times by 25%, proving that formalized contracts scale distributed data modeling.
https://monzo.com/blog/a-meshy-approach-to-data
Aparna Dhinakaran: Context Management in Agent Harnesses

Long-running AI agents degrade as context windows fill with unbounded tool outputs, stale conversation history, and redundant file reads. The author analyzes five agent frameworks—Pi, OpenClaw, Claude Code, Letta, and Arize's Alyx—revealing convergence on hard file caps, token-triggered compaction, and isolated sub-agents. These patterns mirror the classical memory hierarchy—registers, cache, and swap—suggesting that context management is maturing into an invisible system-level discipline.
https://x.com/aparnadhinak/status/2048492731929149929
Spotify: Flow generation through natural language: An agentic modeling approach

LLMs struggle to reason over deeply nested domain-specific schemas that lack representation in pretraining data. Shopify builds a bidirectional transpiler that converts its Flow automation JSON into Python—improving syntactic correctness by 22% and semantic correctness by 13% for its fine-tuned Qwen3-32B model. The approach delivers a Sidekick assistant that runs 2.2x faster and 68% cheaper than the closed-source frontier model it replaces.
https://shopify.engineering/fine-tuning-agent-shopify-flow
Sponsored: The AI Modernization Guide

Will your data platform accelerate your AI initiatives or become their biggest bottleneck? Learn how to build a data platform that's ready for AI:
- Transform from Big Complexity to AI-ready architecture
- Real metrics from organizations achieving 50% cost reductions
- Introduction to Components: YAML-first pipelines that AI can build
Pratish Yadava: Data agents - When enterprise analytics learns to reason
Traditional dashboards answer predefined questions but struggle to diagnose root causes or recommend actions within live business workflows. The author outlines continuous data agents that interpret intent and make bounded decisions—anchored in governed semantic layers and modular, domain-specific orchestrators. This operating model moves analytics from passive reporting into decision-adjacent automation with explicit guardrails and escalation paths.
Pinterest: Smarter URL Normalization at Scale: How MIQPS Powers Content Deduplication at Pinterest
Content platforms waste significant compute re-fetching identical pages, disguised by URL variations introduced by tracking tags, session tokens, and click identifiers. Pinterest engineers MIQPS—a data-driven algorithm that renders pages with and without each query parameter to empirically classify content-changing signals from noise. The system strips redundant parameters at runtime via precomputed offline maps, reducing duplicate fetches and improving catalog deduplication at scale.
Meltwater: Doing More With Less: Rethinking Entity-Level Sentiment at Scale
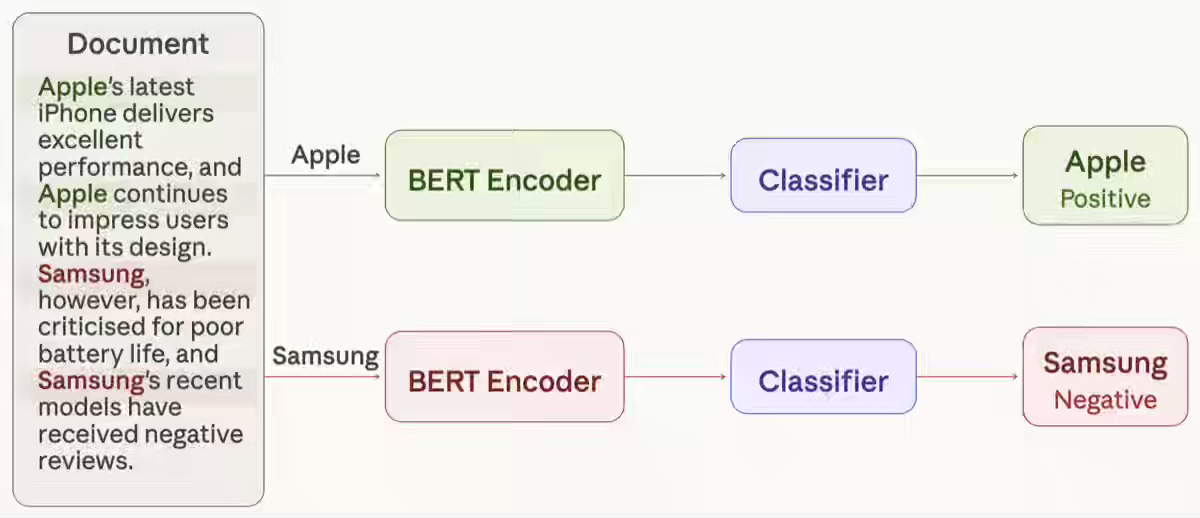
Entity-level sentiment analysis scales linearly when systems re-encode the same document once per entity, multiplying inference costs without improving accuracy. Meltwater extracts per-entity embeddings from a single shared Transformer forward pass, proving that local mention context carries sufficient sentiment signal. The approach reduces inference costs by 45.5% and improves accuracy by 3.02%, converting linear per-entity scaling into near constant-time processing.
https://underthehood.meltwater.com/blog/2026/04/23/rethinking-entity-level-sentiment-at-scale/
Halodoc: Implementing Apache Yunikorn on EMR on EKS at Halodoc
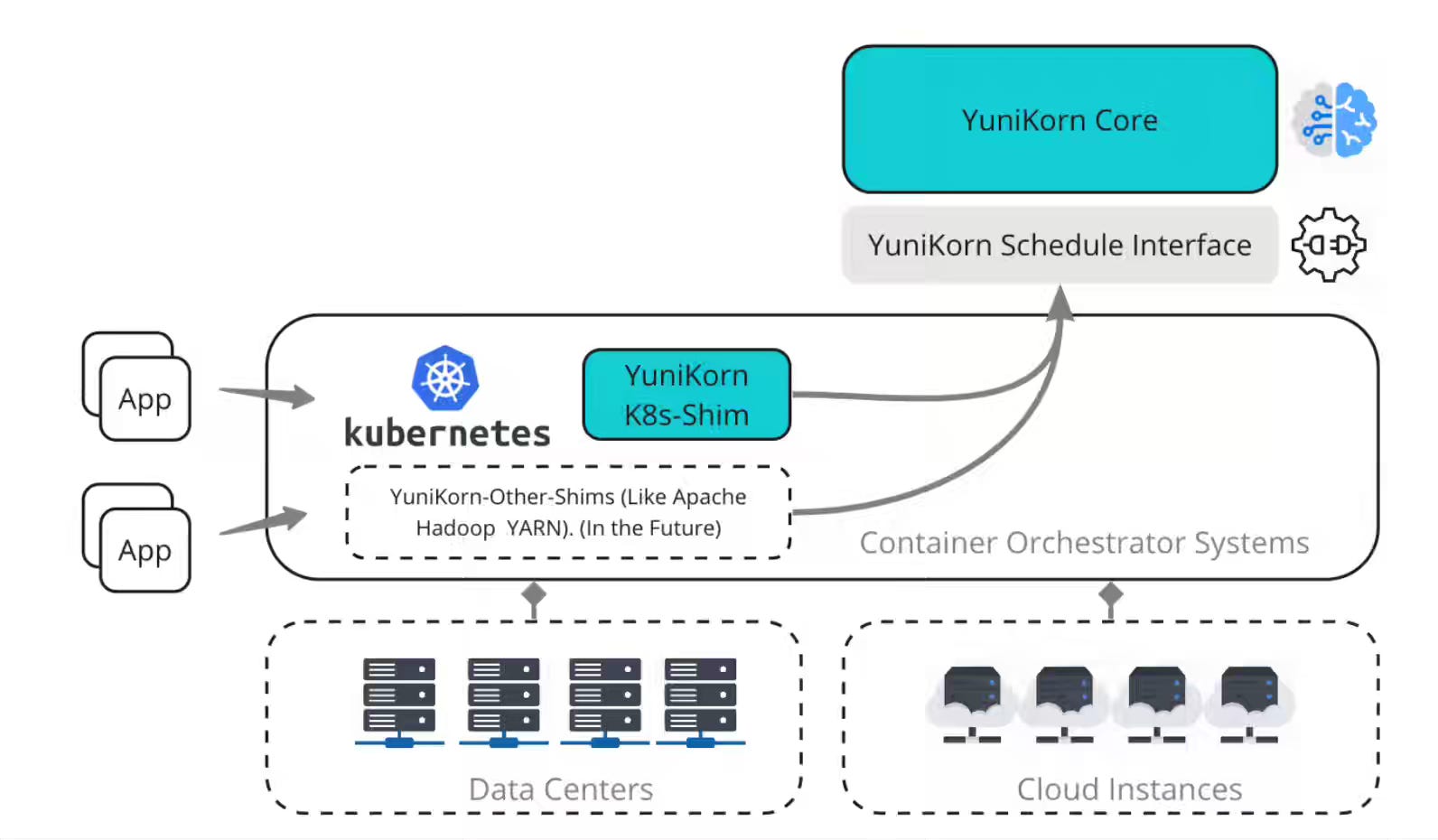
Kubernetes-native Spark workloads trigger aggressive node scaling when the default scheduler evaluates pods independently—causing cost whiplash from rapid scale-outs followed by immediate underutilization. Halodoc adopts Apache YuniKorn's bin-packing strategy to fill existing nodes before provisioning new ones, paired with hierarchical queues that govern cross-team resource boundaries. Node utilization reaches 96%, with a 10% reduction in EC2 costs and increased Spot instance adoption due to improved scheduling predictability.
https://blogs.halodoc.io/implementing-apache-yunikorn-on-emr-on-eks/amp/
Netflix: Scaling Camera File Processing at Netflix
Media production pipelines struggle to manage massive daily camera footage when raw metadata remains unconformed and unsearchable across downstream workflows. Netflix integrates FilmLight's API into its Media Production Suite to parse and normalize camera metadata at ingest—conforming it to a standardized schema that enables automated retrieval and pipeline validation. The system deploys as stateless serverless functions on CPU-only instances, scaling elastically to handle spiky VFX plate generation without dedicated GPU infrastructure.
https://netflixtechblog.com/scaling-camera-file-processing-at-netflix-6dab2b1e80be
Z1: Airflow DAG Bundles: Managing DAGs Across Teams Without Helm Upgrades
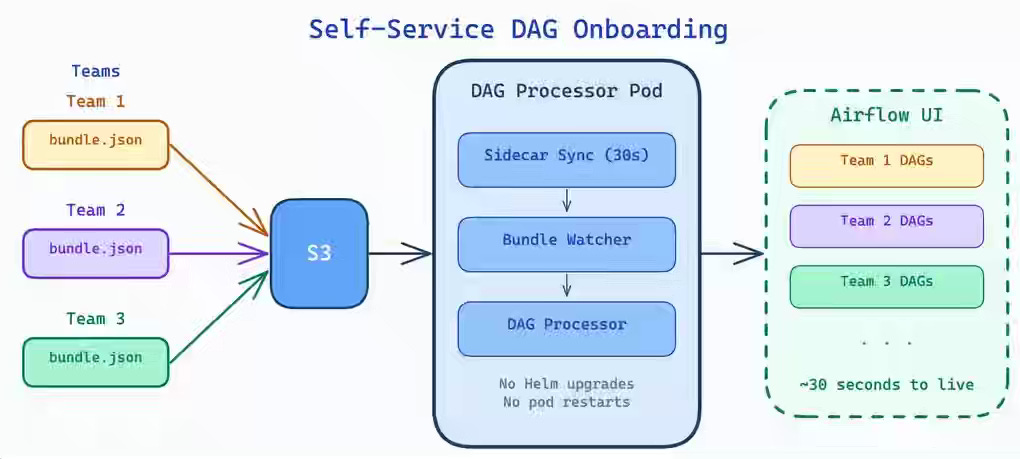
Onboarding new data pipelines in Airflow typically requires Helm upgrades, pod restarts, and infrastructure tickets—turning every DAG addition into a deployment bottleneck. The author leverages Airflow 3.x DAG bundles with an S3-backed sidecar sync pattern that hot-reloads pipeline configurations without downtime or centralized repository dependencies. New DAGs appear in the Airflow UI within 30 seconds of a commit, decentralizing the entire pipeline lifecycle to self-service.
https://blog.platform.zerotoone.ai/blog/airflow-dag-bundles-without-helm-upgrades/
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
