A Practical Guide to Becoming an AI-Native Engineer
来源: ByteByteGo (主流模式)
New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)

Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
Few people in tech have a clearer view of AI-native engineering at hyperscale than Shah Rahman. As Global Head of Autonomous ML Iteration & Optimization for Ads at Meta, Shah spends his days architecting AI-native infrastructure and multi-agent systems that make ML iteration reliable across one of the largest production environments on the planet.
In the piece below, Shah cuts through the “everyone is an engineer now” noise and lays out what AI-native engineering actually requires: context engineering, spec-driven development, critical verification, and disciplined problem decomposition. He walks through the Agentic Development Life Cycle, the journey that separates real 10x leverage from “faster failure,” and the security guardrails that are no longer optional.
If you’re moving your engineering org toward becoming AI-native, this is a strong playbook.
Let’s get into it.
For more from Shah, connect with him on LinkedIn.

AI generates more than 75% of Google’s new code. OpenAI and Anthropic claim that almost every line of fresh code that they produce comes from AI. Amazon recently migrated 30,000 of its production applications from Java 8 to Java 17 in a matter of months, a project that would otherwise have taken an estimated 4,500 developer-years. And Mark Zuckerberg expects that AI agents will be operating as mid-level engineers by the end of 2026.
Reading those statements, we may feel as if we are looking at the last lines being written on the closing pages of an era. Perhaps even the closing pages of a profession.
But here’s the question: If AI writing everything is the answer, then why are most engineering teams shipping more bugs, more incidents, and more technical debt than they shipped two years ago?
In an April article in the New York Times, Mike Isaac and Erin Griffith gave a name to describe what’s happening across the industry. They called it code overload.
The essence of code overload, according to Isaac and Griffith, is that “tech workers are producing so much code so quickly that it has become too much to handle.” Teams that have rebuilt their work around the use of AI agents are drowning in code churn and security holes.
But. Many engineers who have employed AI agents are pulling ahead of the field, achieving real productivity gains. They are using the same models and the same tools, but they are generating very different outcomes. What explains the gap?
It comes down to one decision. Real productivity gains come when engineers decide to make the leap from writing code to orchestrating it. This piece is a working guide for engineers who want to land on the productive side of that split. It will cover the practices, guardrails, and mindset shifts that separate AI-native engineering from vibe coding and from the everyday chaos that most teams are now generating at scale.
From Engineer to Orchestrator
Let me first clarify one thing: engineers are not becoming obsolete. Coding has always been a small part of engineering (20-30% max). This underappreciated reality is more visible when AI agents and tools produce more code, but more code is not necessarily more productive (often it’s less). This is a critical distinction that the industry is blurring dangerously, and I state that as:
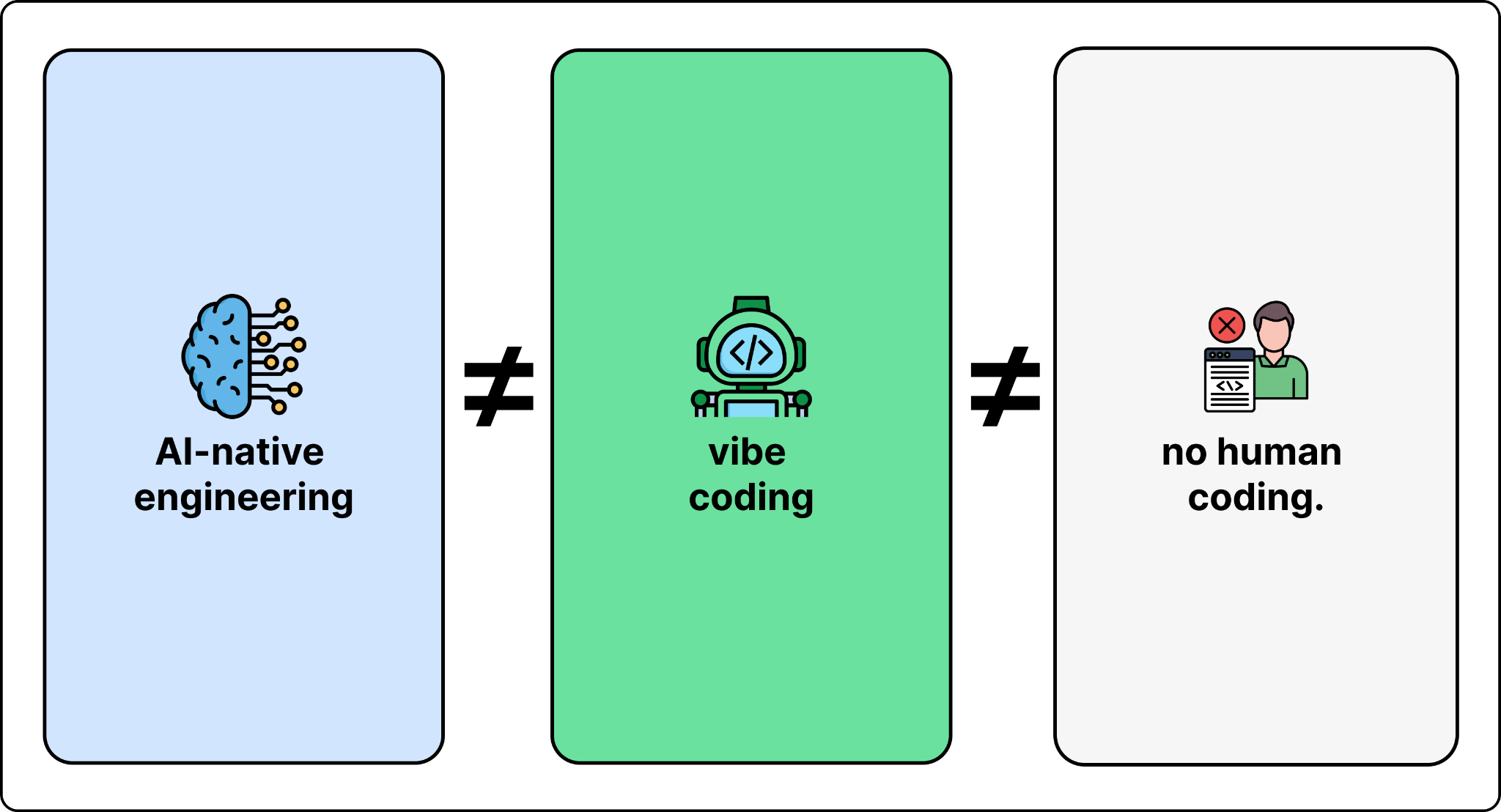
When Andrej Karpathy coined “vibe coding” in early 2025, it captured something useful — the ability for non-engineers to build functional software by describing what they want. That democratization is valuable. But it’s categorically different from professional AI-native engineering.
AI-native engineering means commanding and mastering available and emerging AI agents and tools to engineer things that weren’t possible in the pre-AI era. Knowing how to code remains a fundamental expectation. Without that knowledge, you can build systems using AI — and that’s vibe coding. It has its place, but it’s not engineering.
The AI-native engineer operates as an orchestrator — someone who can turbocharge 10x engineering into 100x output through proper orchestration of AI agents. And that bar continues to rise weekly.
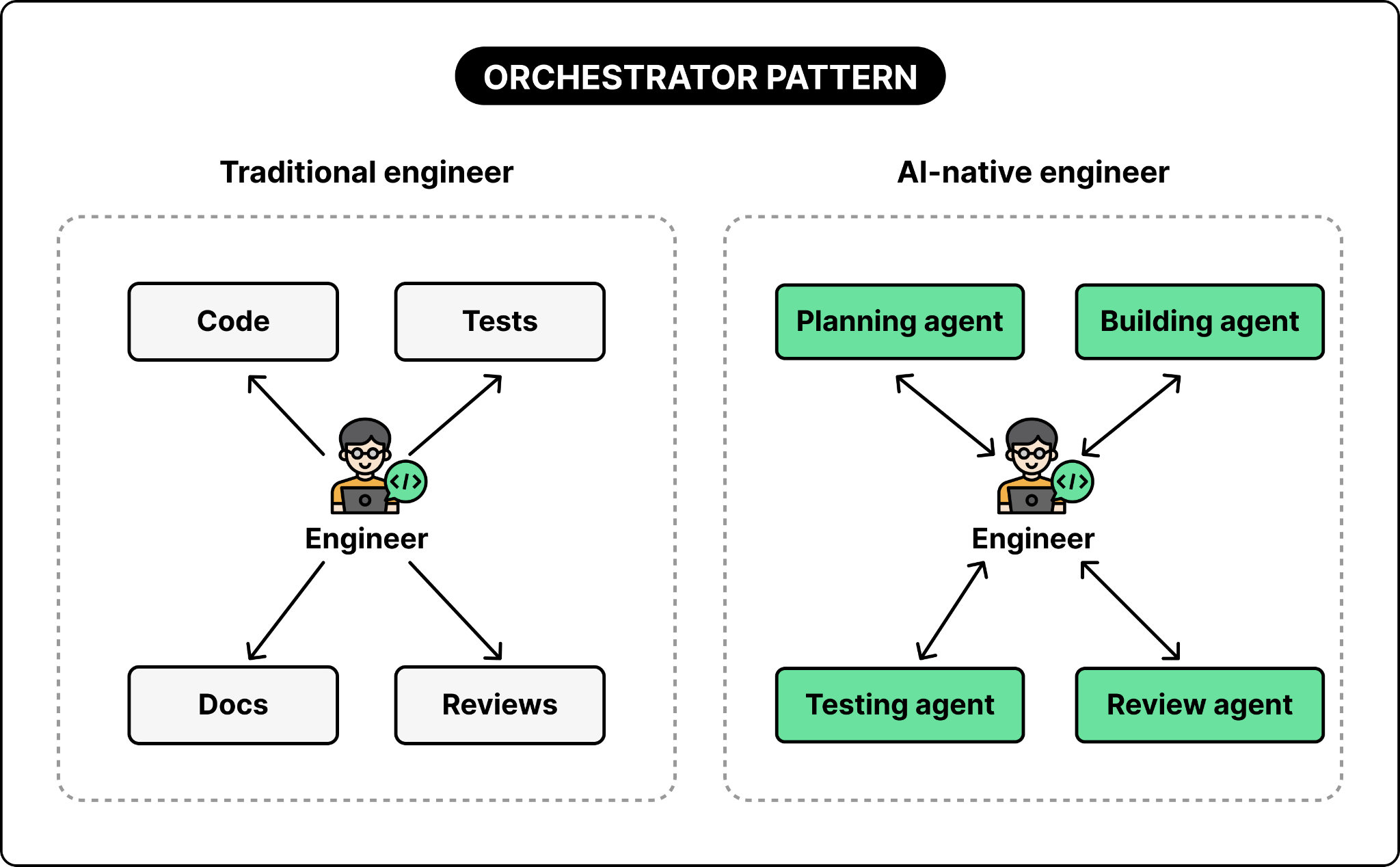
The Four Core Practices
1. Synchronized Context Engineering
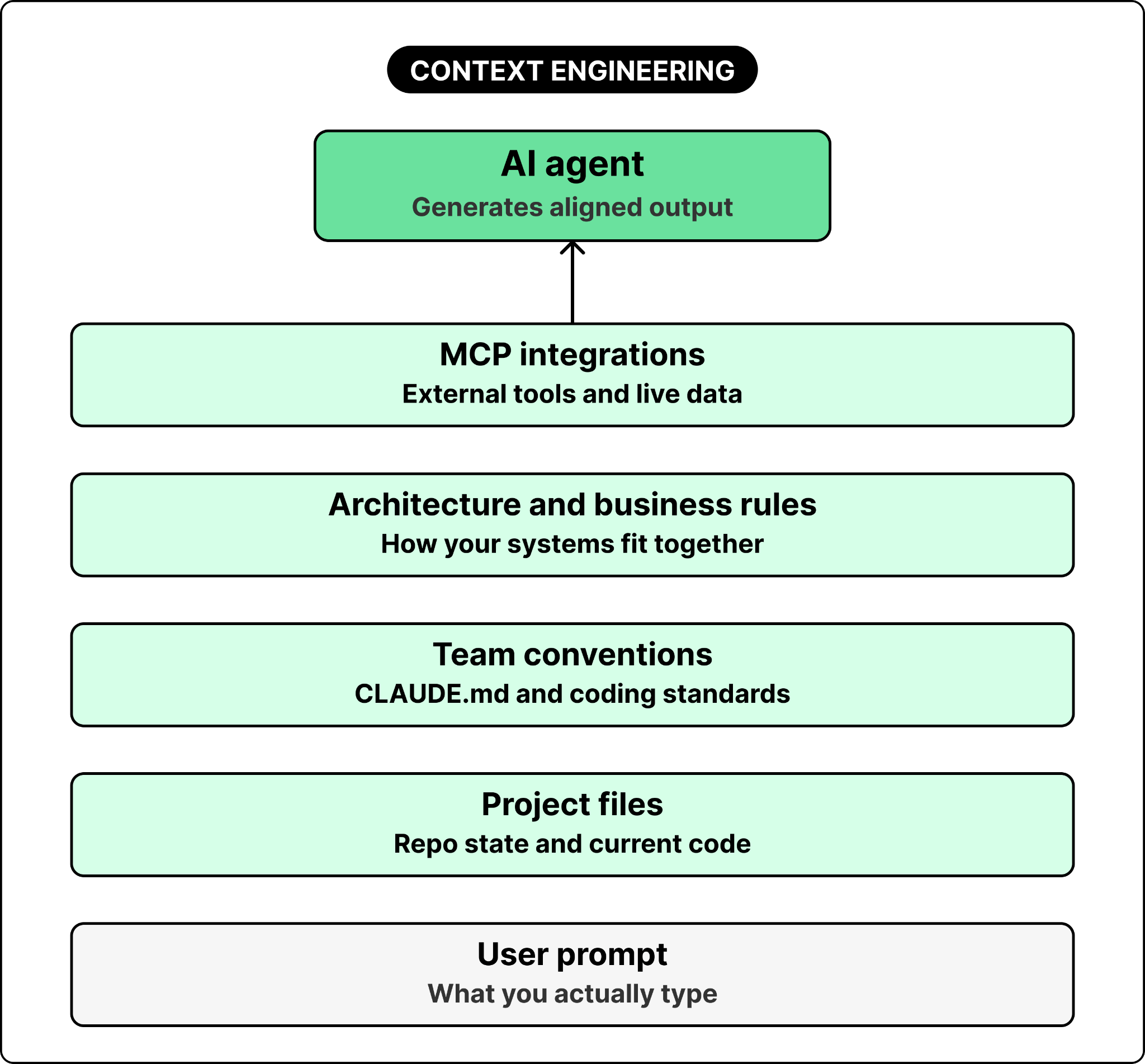
Emerging as a distinct discipline, this is the single most important skill for AI-native engineers. Context engineering means the systematic curation and injection of project-specific information into AI working memory: architectural diagrams, coding standards, business rules, team conventions, and development workflows that are reusable and standardized across your team members.
This shifts basic “prompt engineering” to sophisticated “context engineering” reflecting a deeper understanding: the quality of AI output is bounded by the quality of context it receives. Teams practicing rigorous context engineering report 40–50% speed increases and dramatically reduced alignment overhead.
As context engineering matures, Anthropic’s MCP — described as “USB-C for AI” — continues to be a universal standard for connecting agents to external tools and data sources. Context files like CLAUDE.md have become core infrastructure, not optional documentation. This persistent, evolving knowledge layer makes agents genuinely useful within your specific codebase, once you master developing and maintaining this critical context.
2. Specification-Driven Development
The quality of AI-generated code matches the quality of input specifications. Garbage in, garbage out — this principle applies with even more force when AI can generate garbage at unprecedented speed and volume.
Random prompting and vibe coding consistently underperform spec-driven workflows. AI agents get stuck in circular reasoning without clear specifications and instructions that are contained and well-defined. Consider this discipline: define what you want before asking AI to build it, break problems into discrete milestones with clear success criteria, and execute incrementally with validation at each checkpoint. Make sure the agent checks all open Qs with you and doesn’t run off on its own to find answers.
3. Critical Verification
AI-generated code quality approximates that of early-career developers. Research consistently shows that around 45% of AI-generated code contains security flaws. A Stanford study found that developers using AI assistants wrote significantly less secure code and were more confident it was secure — a dangerous combination.
Meanwhile, a striking METR/Anthropic randomized controlled trial found experienced open-source developers were actually 19% slower when using AI assistants on familiar codebases. The culprit? Over-reliance without adequate verification. A GitClear study found AI-assisted codebases showed increased “code churn” — code written and then quickly revised or deleted — suggesting raw output is a poor proxy for productivity.
In the AI-native era, the bottleneck has permanently shifted from writing code to proving that it works at scale, with reliability and security. When AI generates code quickly, review, testing, and verification of that code become the new rate-limiting factors, and verification now becomes non-negotiable.
4. Problem Decomposition
Avoid over-trusting AI with large, complex problems. Break tasks into AI-manageable chunks where humans handle edge cases, custom logic, and domain-specific aspects while AI agents handle the 70–80% of routine implementation. Complex problems lead to context pollution and slop generation that AI agents really struggle to recover from. Compacting and summarizing when context is polluted and shifting to a different session helps, but this discontinuity can be damaging for long-horizon tasks.. Many of us wasted hours, if not days, due to not decomposing and stubbornly confusing agents about expectations outside of a well-defined context, reasonable specifications, and a lack of verification guardrails.
Time Allocation for AI-Native Work
I recommend the optimal split of: 40% context-setting, 20% generation and testing iteration, 40% reviewing and verification. This surprises many developers who spend most of their time in code generation. In practice, the generation step is fast; the verification and context work become the new time sink.

The Individual Transformation Journey
Phase 1: Foundation — should only take a couple of weeks
Begin with one primary AI assistant — pick your favorite one: Codex, Claude Code, or Cursor. Dive deep and build intuition for its capabilities and limitations through daily practice. Set up your workspace, workflow, and initial configurations. You’ll have to take the leap from the times of manual coding to AI-assisted and AI-generated coding practices. Your goal should be to develop judgment about when AI delivers value versus when it creates more work than it saves. Write down your personal notes, iterate, and build a strong foundation.
Phase 2: Integration — should take a month max
Adopt structured prompting frameworks. Create project-specific context files encoding team standards and architectural patterns. Implement the “Plan first, then Execute and finally review” workflow: planning mode generates specifications, execution mode implements, and make sure you review after each atomic task. Establish approval gates and guardrails that prevent agent drift. Skipping the review will pile tech debt that you and your agent will both struggle downstream.
The critical practice here is small loops with verification checkpoints. Evidence shows tight human-in-the-loop cycles with limited scope dramatically outperform large autonomous runs, at least for coding tasks. This may feel counterintuitive and slower — but it produces dramatically better outcomes in practice. Indulging into somewhat unplanned and speculative autonomous agent runs will likely produce a large volume of slop whose only destiny may be throwaway and start all over again. Avoid that before it happens.
Phase 3: Mastery — live on
Deploy AI agents for multi-step, multi-file tasks. Implement AI-assisted code review workflows. Use advanced techniques: multi-agent workflows, parallel sessions, and cross-agent verification loops. Every week, we hear about coding agents advancing on benchmarks and solving problems that were never solved before. Stay on top of those developments and embrace what Claude or Codex inventors are advocating, but adopt those to your needs (don’t blindly follow as their situations may be wildly different than yours).
Target metrics: 80%+ AI-generated coding rate with less than 20% rewrite rate. Achieve this, and you can pull your team toward the same proficiency level rather fast.
Team Transformation: The Cultural Foundation
Research shows 70% of transformation success comes from operational and cultural change. These changes call for Organizational and technical leads to actively model transformation through daily AI usage. At the same time, ensure three critical aspects to establish the AI-native cultural foundation:
Psychological safety is paramount. MIT research found 83% of leaders believe psychological safety measurably improves AI initiative success. Celebrate “AI failure stories” as learning opportunities. Make this deliberate practice, not optional and ensure everyone feels included as part of the collective learning and growing exercise.
Evolved code review is essential. AI-generated code volume overwhelms traditional human review processes. Redesign review to distinguish AI-generated versus human code with separate review rubrics. Be especially vigilant about the dangerous combination of AI-generated and AI-reviewed PRs — these combinations should be explicitly guardrailed and governed, when necessary.
Shared context libraries become the core currency. Standardize context files, evaluation sets, and agent configurations across teams. Modern tooling enables easy packaging of context through plugins, skills, and commands — but watch for uncontrolled proliferation, where teams compete for standardization rather than collaborating. Don’t let too many team members’ desire to build agents and skills jeopardize your standardized agentic operating environment.
The Agentic Development Life Cycle (ADLC)
Traditional SDLC — and even extreme agile — falls short for how AI agents develop software alongside humans. AI-native engineering evolution toward an Agentic Development Life Cycle redefines each phase.
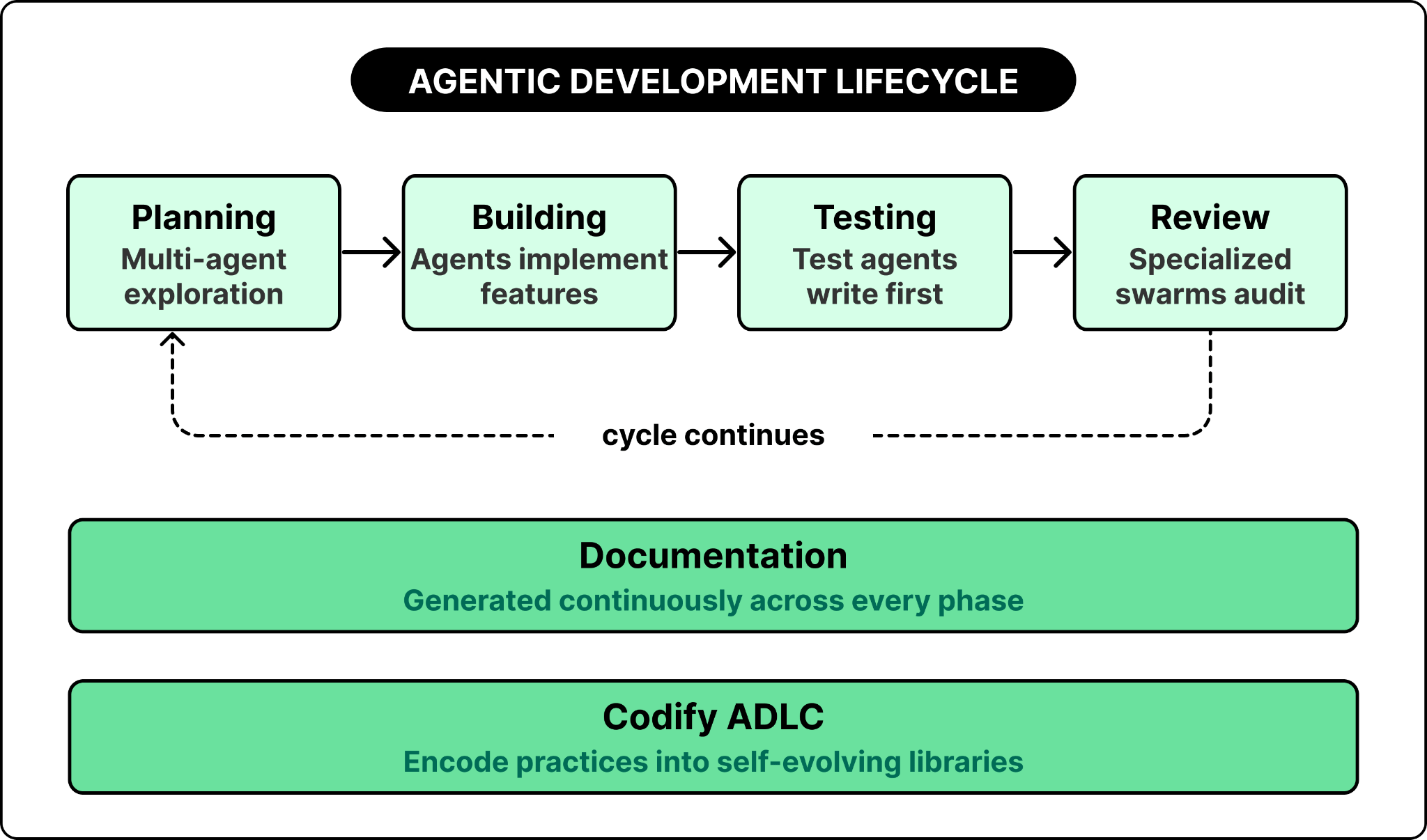
Planning
The most critical step. Use deep research and planning modes with multiple agents for parallel exploration. Specify against codebases, flag ambiguities, decompose into subtasks, and estimate difficulty. Create roadmaps with version milestones that help agents follow through incrementally. A planning agent can assemble findings from multiple exploration agents into a coherent implementation strategy. OpenClaw of Claude can run in multiple sub-agent in parallel.
Building
AI agents handle end-to-end feature implementation like junior or mid-level engineers (at the time of this writing, which I expect to edge up to senior engineers within a year or two). The engineer acts as the tech lead, orchestrating multiple agents rather than coding directly. Sequential or parallel execution models depend on your roadmap and verification plan. The agentic coding tool landscape has matured rapidly — Claude Code, Cursor’s Composer mode, GitHub Copilot’s Agent Mode, and OpenAI’s Codex agent all support this pattern with varying strengths. There’s new versions coming out every month -- watch closely for new capabilities.
Testing
This is TDD reincarnated. Agents write test plans first, then implement code. All tests should fail at the beginning and then incrementally pass. Unit testing at the atomic level, integration testing across features, and end-to-end testing across the system. Don’t overindex on unit testing at the expense of integration or system testing lack.
Pro Tip: Consider separating planning, building, and testing agents. Each agent swarm specializes and develops a deep understanding of your codebase from a different perspective. Planning agents can challenge building agents who take shortcuts; testing agents who skip coverage; or the review agents who are biased towards incorrect implementations that appear to be correct. Similarly, review agents can hold every other upstream agent accountable for making mistakes or missing steps.
Review
Deploy agent swarms specializing in key dimensions: functionality, quality, scalability, performance, reliability, security, and privacy. Agents take the first pass and produce reports; humans review each report carefully. When one agent discovers an issue — say, an injection vulnerability — apply the generalization principle: if one instance exists, others likely do too and this is your chance to proactively similar a vulnerability type in your code, not just one or two instances.
Documentation
Move from post-facto documentation to continuous generation. AI agents generate summaries, key design decisions, architectural diagrams, and changelogs in real time. This flows naturally into API documentation, feature collaterals, and customer-facing contents. I’m quite excited about AI tools finally solving the outdated, stale, and inconsistent documentation problem that I’ve seen myself and my teams suffer for decades.
Codify ADLC
Encode your Layer-1 (individual) and Layer-2 (team) practices into maintained, self-evolving context files, skills libraries, and MCP tools. This ensures ADLC adoption scales across the organization rather than remaining tribal knowledge or trapped in parts of the org. Promote the ADLC tooling package.
What AI-Native Process Actually Looks Like
There’s a seductive narrative in the industry right now: fewer people, less overhead, faster builds. But this narrative conflates construction costs with decision costs. AI has drastically reduced the cost of building, but that represents only 20–30% of total development costs, while leaving the cost of deciding what to build and what to cut largely untouched. With the proliferation of code and builders, this becomes a harder problem.
AI-native process optimization requires redirecting effort from coordinating execution to accelerating learning.
The Learning Loop
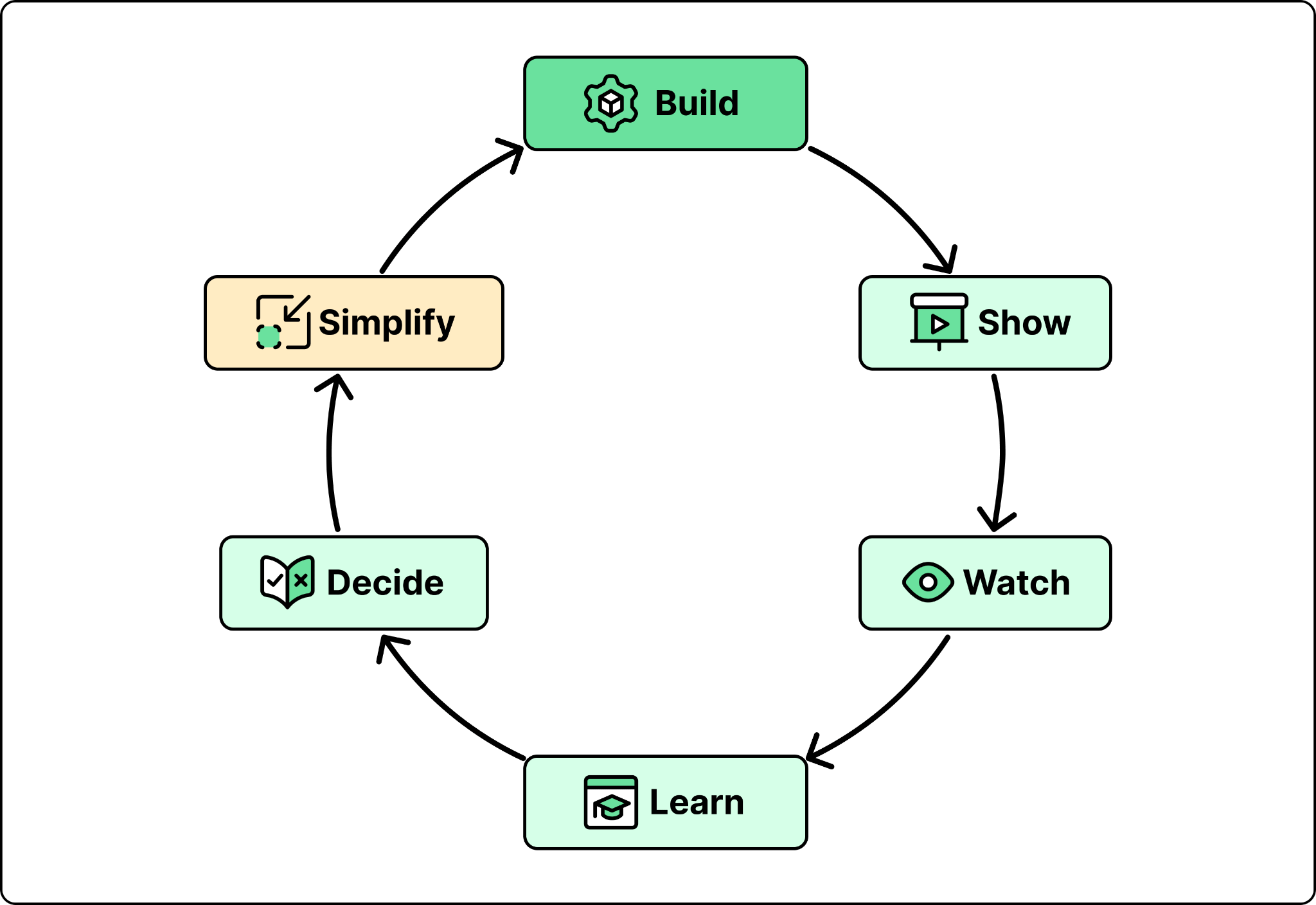
AI compresses the first step dramatically. But compression value depends entirely on execution quality throughout the remaining cycle. Faster building without robust user observation and scope discipline produces faster divergence from genuine product goals. This results in customers not seeing the benefits of AI acceleration.
Where AI Creates Genuine Leverage
Cheaper experimentation. Test more hypotheses per unit time. Over 70% of features never reach real users. AI makes it trivially cheap to test whether something matters before committing to full development. The discipline: kill non-viable concepts ruthlessly.
Faster prototyping for user research. Working prototypes replace documentation. Tools like Vercel’s v0, Replit Agent, and Bolt.new enable functional prototypes from natural language in minutes. This produces superior signal quality from user testing. Encourage everyone to prototype aggressively, make it a habit before you build.
Automated boilerplate, not automated judgment. AI handles undifferentiated work: scaffolding, non-novel code, business logic tests, documentation, and data models. Teams focus on differentiated work: core business logic, empathetic user experiences, novel implementations, and the crucial decision of what to keep or kill.
The “design to 50%” principle. Ship minimal functionality enabling core user journeys. Observe where users hesitate, misunderstand, or abandon. This reveals actual product challenges rather than imagined ones. AI makes this approach nearly zero cost.
Guardrails — Not Optional
The security landscape for AI-generated code has become genuinely alarming. The data shows AI-native development speed is creating new attack surfaces faster than manual security review or traditional tools can address. We observed roughly one new insecure AI integration appearing per week in our environment, many resulting in production incidents. Anthropic’s Daybreak and Mythos bring a clear wake-up call to security.
Real Incidents, Real Consequences
Chat Integration RCE. Built in two days using AI, achieved Remote Code Execution by bypassing 2FA and exploiting open ACLs. It costs tens of hours to detect, mitigate, and fix.
Unauthorized Database Access. An AI coding agent accessed approximately 1,500 secure, unauthorized database tables without proper authorization, exposing sensitive data to prompt injection risks.
Google Docs Prompt Injection. An AI coding agent achieved Remote Code Execution through prompt injection embedded in a Google Docs document, bypassing input filtering protections entirely.
Supply Chain Poisoning. A new attack vector called “slopsquatting” emerged in 2025 — AI models hallucinate package names that don’t exist, and attackers register those names with malicious code. Multiple documented incidents have resulted from this.
Emerging Security Controls
Agent Identity and Access Control. Implement step-up 2FA. Apply the principle of least privilege. No shared credentials or open ACLs. Start with passive, read-only use cases and build confidence before granting read-write or broader access.
Data Classification Awareness. Agents must respect data classifications and sensitive boundaries. “Agentic Authorization” is an emerging enterprise challenge where agents bypass restrictions at machine speed that human oversight cannot match.
Prompt Injection Protection. External content — documents, web pages, user inputs — can contain hidden instructions that hijack agent behavior. Implement input filtering, content validation, and context sanitization. Never auto-execute untrusted commands. Resist the temptation of auto-accepting all agent suggestions.
Infrastructure Sandboxing. Agent activities must be observable and auditable. Block high-risk production surfaces — configurations, critical execution, critical storage — until controls are verified. Use sandboxing and OS-level enforcement.
Technical Guardrails
Static analysis integration. Data shows roughly 30% of Python and 25% of JavaScript AI-generated snippets contain security weaknesses. Centralize advanced static analysis in CI/CD pipelines. Require mandatory human review for critical functions: authentication, payments, and PII handling.
Automated quality gates. Implement “Ralph Loops”, OpenClaw, or another form of autonomous loops — iterative verification until success criteria are met. Type checking, linting, and test execution before diff submission. Multi-stage canary systems with stringent gates before production deployment.
Skills-based security. Where the agents are taught secure coding patterns, flagging common vulnerabilities during generation rather than after. Shift left, but with agents.
Organizational Guardrails
Skill atrophy prevention. Gartner reports 50% of organizations will require “AI-free” skills assessments by 2026. Treat AI as a learning tool — request explanations alongside generated code. Occasionally, work without AI to preserve foundational abilities. The goal isn’t Luddism; it’s insurance against the day your AI tools are unavailable or producing subtly wrong, but potentially fatal results.
The productivity paradox. Individual productivity gains from AI tools often fail to materialize at the team and company levels. Focus on end-to-end cycle time and feature velocity, not coding speed alone. Adding AI to broken processes yields broken processes that generate more code, faster.
The Engineer of 2026 and Beyond
The engineers thriving in the new environment treat AI as a collaborative partner for execution while maintaining the systems thinking, critical judgment, and communication skills that no AI can replicate. AI amplifies existing expertise rather than replacing it — senior engineers achieve dramatically better results because they bring deeper context and sharper judgment.
Your domain expertise is the key differentiator in AI-native productivity. No AI tool or agent can replace it. So, invest in sharpening your domain skills, whether that’s math, science, finance, health science, or a legal profession. Continuing to uplevel your engineering fundamentals pay recurring dividends in AI effectiveness.
This is a multi-year transformation, not a one-off tool adoption. Teams treating it as a tooling upgrade consistently fail to realize productivity gains. The organizations that succeed are the ones treating AI-native engineering as a new way of working — with new practices, new disciplines, and new definitions of what “amazing” looks like.
Are you building this way yet? If not, ping me, and I’m happy to have a chat.
This is Part 1 of a two-part series. Part 2, “AI-Native Leaders,” covers the organizational transformation, leadership models, and measurement frameworks required to make AI-native engineering work at scale.