数据工程周刊 #244
Source: Data Eng Weekly

The data platform playbook everyone’s using
We wrote an eBook on Data Platform Fundamentals to help you become like the happy data teams operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Editor’s Note: Re:Govern: The Data & AI Context Summit
Data engineering is evolving. Learn how from the top 5% of teams who are leading the way. There’s no playbook for data teams in the AI era. However, some leaders aren’t waiting for one — they’re building in real-time and sharing what they learn.
That’s why I’m excited for Re:Govern 2025 on November 5. Leaders from Mastercard, GitLab, General Motors, Elastic, and others are opening up about what’s working: how they’re training AI to understand business context, delivering data products built for AI from the ground up, and restructuring their teams for a world where agents do the heavy lifting. These are the unfiltered lessons from teams who are years ahead — not because they had all the answers, but because they started moving first.
Register here. Don’t miss this one.
Matt Turck: Bubble & Build: The 2025 MAD (Machine Learning, AI & Data) Landscape

The AI and data ecosystem is experiencing both speculative exuberance and genuine transformation as systems evolve from chatbots to agentic architectures grounded in governed data and reasoning models. Matt Turck’s 2025 MAD Landscape captures this inflection—highlighting reasoning + RL breakthroughs, the merging of data and AI infrastructure, sovereign compute buildouts, and the rise of coding agents and multimodal applications.
https://www.mattturck.com/mad2025
Gradient Flow: Reimagining the Database for AI Agents

In the past, I wrote about “Supporting Our AI Overlords” and “Semantic Spacetime.” Tell Us About the Future of Data Infrastructure captures some of the unique challenges associated with the current data infrastructure in supporting speculative execution from the Agentic workload. The blog highlights some of the recent attempts to reimagine the data infrastructure to purpose-fit design for the agentic workflow.
https://gradientflow.substack.com/p/inside-the-race-to-build-agent-native
Eran Stiller: The Architectural Shift: AI Agents Become Execution Engines While Backends Retreat to Governance

Enterprise systems struggle to scale intelligent automation when AI remains confined to assistive or recommendation roles. The author writes how the enterprise is adopting a new architecture where agents, powered by the Model Context Protocol (MCP), directly invoke services, execute transactions, and orchestrate workflows—while traditional backends retreat to governance and policy enforcement. Early deployments across banking, healthcare, and retail show agents operating as execution engines, enabling faster, more adaptive operations and redefining enterprise software around autonomy and trust.
https://www.infoq.com/news/2025/10/ai-agent-orchestration/
Sponsored: How PostHog Powers Customer-Facing Web Analytics with Dagster

When PostHog’s enterprise customers couldn’t load their Web Analytics dashboards due to billions of monthly events, the team transformed weekend manual backfills into automated, reliable pipelines that power customer-facing features at scale.
Find out how the PostHog team built their solution with Dagster.
Piotr Mazurek & Felix Gabriel: LLM Inference Economics from First Principles
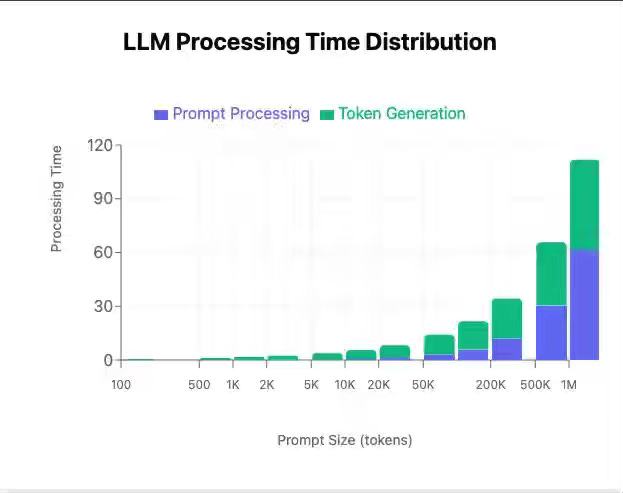
Profitability in large language model (LLM) APIs hinges on mastering inference economics, where compute and memory bandwidth costs determine token pricing and model accessibility. The author breaks down Llama 3.3 70B’s inference dynamics—from compute-bound prefill phases to memory-bound token generation—showing how batching, GPU parallelism, and KV-cache management shape throughput and unit cost. This first-principles framework reveals that efficient batching and memory utilization, not raw compute scale, drive sustainable margins and democratize AI deployment.
https://www.tensoreconomics.com/p/llm-inference-economics-from-first
Zillow: Beyond Clicks: Designing AI-Driven User Memory for Personalization
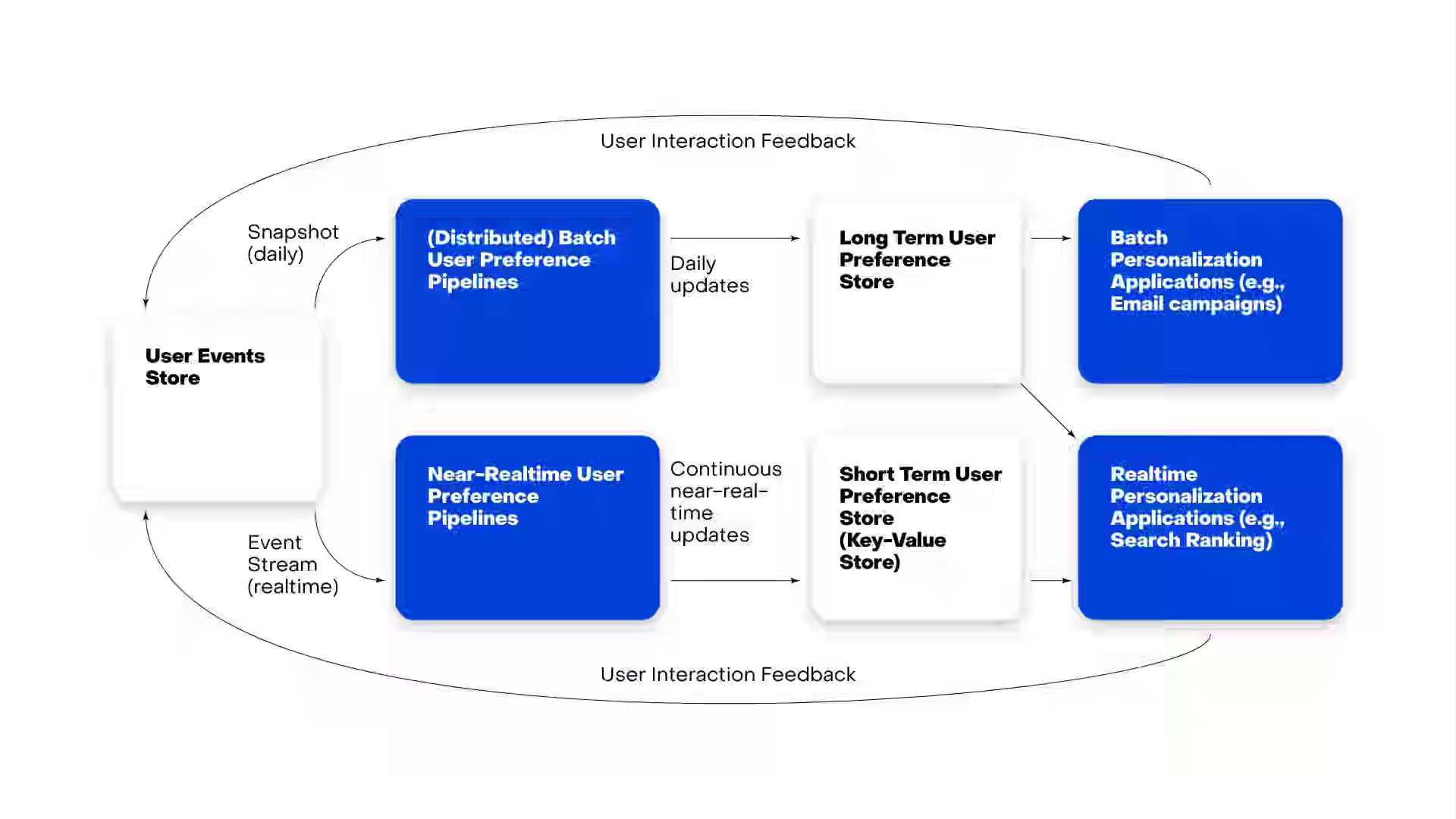
Static personalization breaks down when home-shopping intent shifts over weeks or months. Zillow builds an AI-driven “user memory” layer—comprising recency-weighted preference profiles, affordability-aware models, deep embeddings, and raw interaction history—fed by hybrid batch and real-time pipelines to capture both durable intent and in-session signals. The result is responsive, trust-centered recommendations that stay consistent across surfaces, adapt to changing goals, and help buyers and renters make confident, long-horizon decisions.
https://www.zillow.com/tech/designing-ai-driven-user-memory-for-personalization/
Meta: Ladder of evidence in understanding the effectiveness of new products
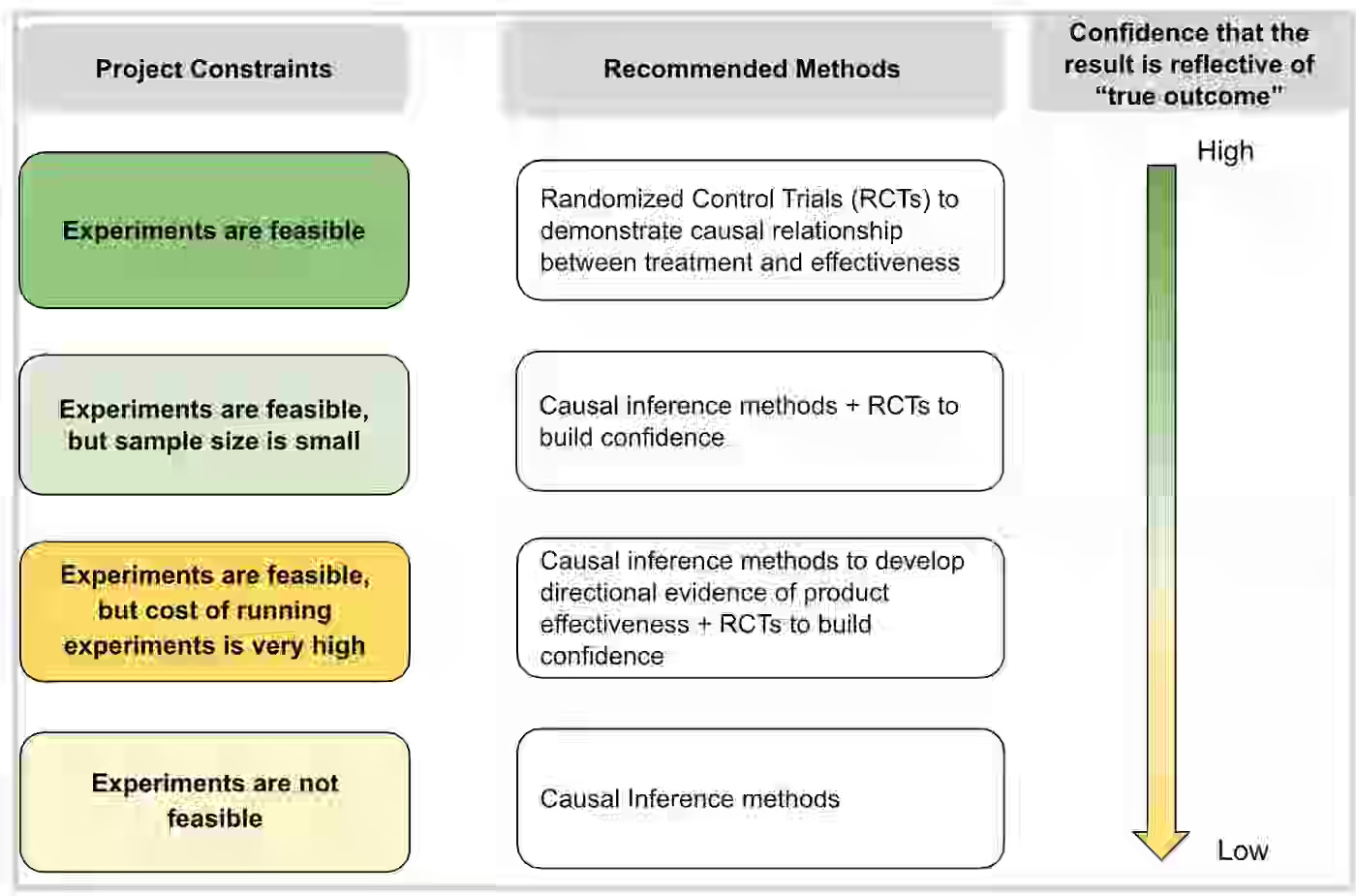
Product teams often struggle to measure true effectiveness when randomized experiments are infeasible or underpowered. Meta outlines a decision framework—choosing between Randomized Controlled Trials (RCTs), causal inference methods, or both—based on project constraints, confidence needs, and analytical influence across a product’s lifecycle. By aligning statistical rigor with practical feasibility, data scientists can balance causation and correlation, communicate confidence transparently, and guide product decisions with evidence that scales from early prototypes to full launches.
Whoop: Glacierbase: Managing Iceberg Schema Migrations at Scale

Large-scale data platforms often struggle to evolve Iceberg schemas safely across environments without risking drift or performance regressions. WHOOP built Glacierbase, a version-controlled migration framework that treats schema changes as immutable, reviewable artifacts—integrated with Spark, Snowflake, and other open table runtimes—to enforce consistency, auditability, and atomic execution. By aligning schema evolution with engineering workflows and CI/CD, Glacierbase turns table management into a reliable, code-driven process that scales with petabyte data lakes while preserving performance and governance.
https://engineering.prod.whoop.com/glacierbase/
Monday Engineering: Reading from DynamoDB Streams without Lambda
Building low-latency change data capture (CDC) pipelines on DynamoDB Streams is challenging when relying on AWS Lambda’s limited polling frequency. The blog talks about a custom Go-based listener that directly consumes the DynamoDB Streams API, utilizing a distributed design of Leaders, Readers, and Processors to balance shards, ensure fault tolerance, and achieve sub-300 ms latency.
https://engineering.monday.com/reading-from-dynamodb-streams-without-lambda/
Yaroslav Tkachenko: Flink Forward 2025 - Conference highlights
Streaming practitioners continue to refine large-scale data processing as Apache Flink evolves toward higher performance and richer developer tooling. The author summarizes the key moments of Flink Forward - 2025.
Ververica announced VERA-X, a vectorized Flink runtime inspired by Alibaba’s “Flash,” alongside deeper integration of Apache Fluss.
Talks from Shopify, LinkedIn, and others showcased advances in multi-way joins, Iceberg sinks, and real-time AI with Flink SQL
https://www.streamingdata.tech/p/flink-forward-2025
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
