Data Engineering Weekly #256
Source: Data Eng Weekly

What assets do best: The Dagster Children's Book
We’re excited to share something a little unexpected from the Dagster team: What assets do best, a children’s book about data assets! Perfect for kids and data-loving grown-ups alike, you’ll learn how assets work together, adapt to change, and give teams a complete view of their data.
Watch the narrated story, find out where you can snag a free book IRL, and print & play puzzles!
Check out the book & other activities
Alexander Shereshevsky: Graph RAG in 2026 - A Practitioner’s Guide to What Actually Works
Graph RAG adoption stalled after early hype because high indexing costs and unclear performance trade-offs limited production use. The article explains when Graph RAG outperforms vector search, how teams reduce costs with selective graph construction, and why hybrid vector–graph architectures deliver the best results.
Mark Rittman: So, Just How Relevant is Multi-Touch Attribution for Marketers in 2026?
Marketing attribution struggles in 2026 as privacy controls, regulations, and cookie loss remove large portions of user-level data. The article explains how teams adapt by combining deterministic identity for logged-in users, server-side tracking, and triangulation across MTA, MMM, and incrementality testing. Prioritizing authentication, tracking micro-conversions, and owning raw event data enables more reliable attribution in a privacy-first environment.
https://blog.rittmananalytics.com/how-relevant-is-multi-touch-attribution-for-marke-275a71a36d5e
Pinterest: Next Generation DB Ingestion at Pinterest
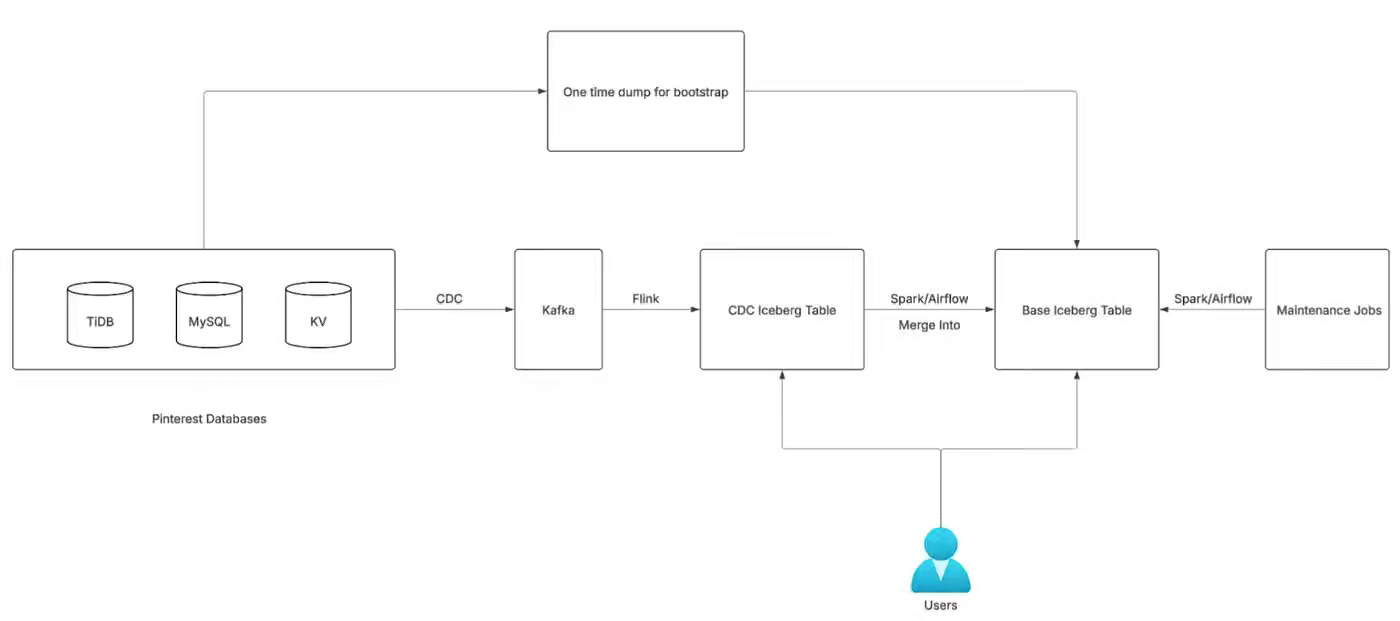
Legacy batch-based ingestion pipelines created high latency, operational complexity, and compliance gaps across Pinterest’s data ecosystem. The article explains how Pinterest built a unified CDC-based ingestion framework using Kafka, Flink, Spark, and Iceberg to stream database changes and efficiently upsert them into analytical tables, reducing data latency from days to minutes while lowering compute costs and improving reliability at the petabyte scale.
https://medium.com/pinterest-engineering/next-generation-db-ingestion-at-pinterest-66844b7153b7
Sponsored: Dagster Running Dagster

In this upcoming session, find out how Dagster's data team has increased its capacity, along with best practices for data modeling that work well with AI assistants. We'll also demo a real case where our Compass Dagster+ integration identified the root cause of a Postgres-to-Snowflake pipeline that was failing 40-50% of the time.
Netflix: The Data Canary: How Netflix Validates Catalog Metadata
Although this article is not specifically about the data warehouse, it demonstrates how data corruption can occur without a code change and still disrupt the system. The article describes how Netflix built a data canary system that validates new catalog metadata using side-by-side clusters, chaos-based testing, and customer-centric behavioral metrics. By detecting corruption within minutes and blocking the release of unsafe data, Netflix applies code-level deployment rigor to high-velocity data pipelines.
Uber: Introducing uFowarder - The Consumer Proxy for Kafka Async Queuing
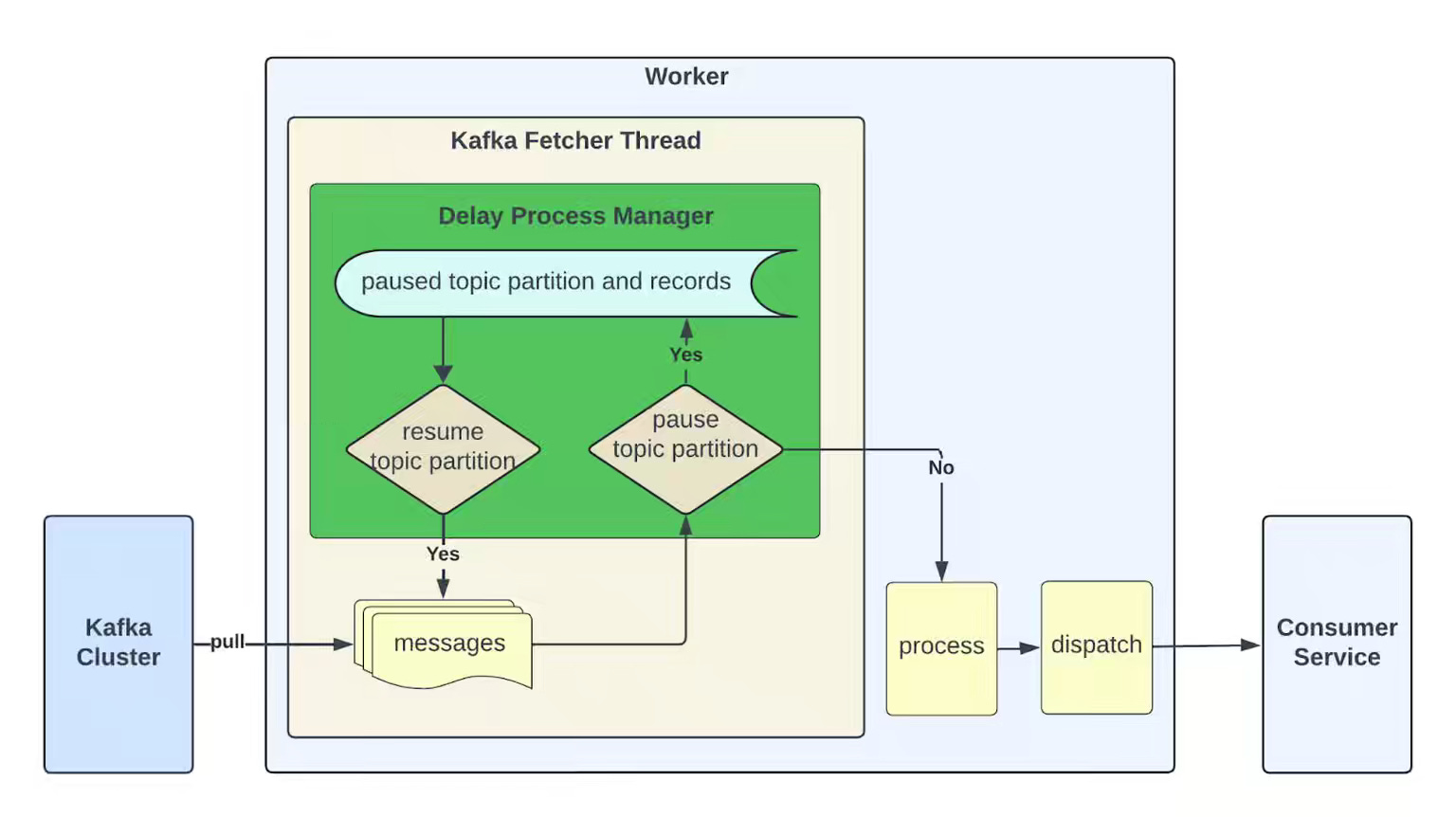
Kafka consumer services struggle to scale reliably when direct protocol access introduces head-of-the-line blocking, inefficiency, and operational complexity. The article explains how Uber built uForwarder, a gRPC-based Kafka consumer proxy that resolves head-of-line blocking, improves hardware utilization, isolates traffic, and supports delayed processing. By abstracting Kafka internals behind a push-based interface, uForwarder increases reliability and efficiency across thousands of consumer workloads.
https://www.uber.com/en-IN/blog/introducing-ufowarder/
Pierce Lamb: Agentic Search over Graphs of Long Documents (or LAD-RAG++)
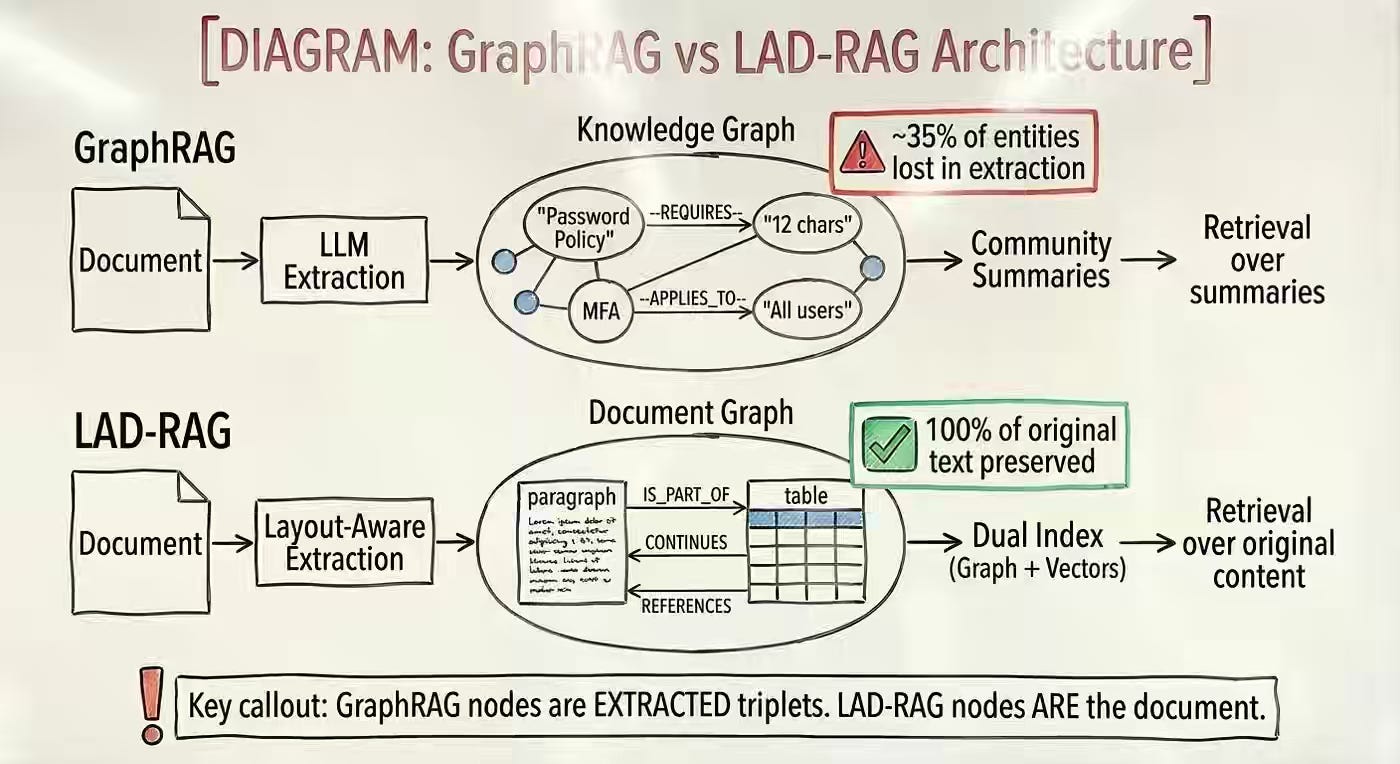
Possibly one of the best reads for this week for me. Vanilla RAG struggles with long, structured documents because static chunking loses layout, relationships, and cross-page context. The author reviews LAD-RAG++, which constructs layout-aware document graphs and employs agentic retrieval to explore structural and semantic connections dynamically. Engineering improvements in memory control, graph pruning, and cost-efficient processing make graph-based RAG practical for high-recall question answering over dense professional documents.
https://pierce-lamb.medium.com/agentic-search-over-graphs-of-long-documents-or-lad-rag-1264030158e8
Halodoc: Halodoc’s Layered Data Validation Strategy for Building Trust in the Lakehouse
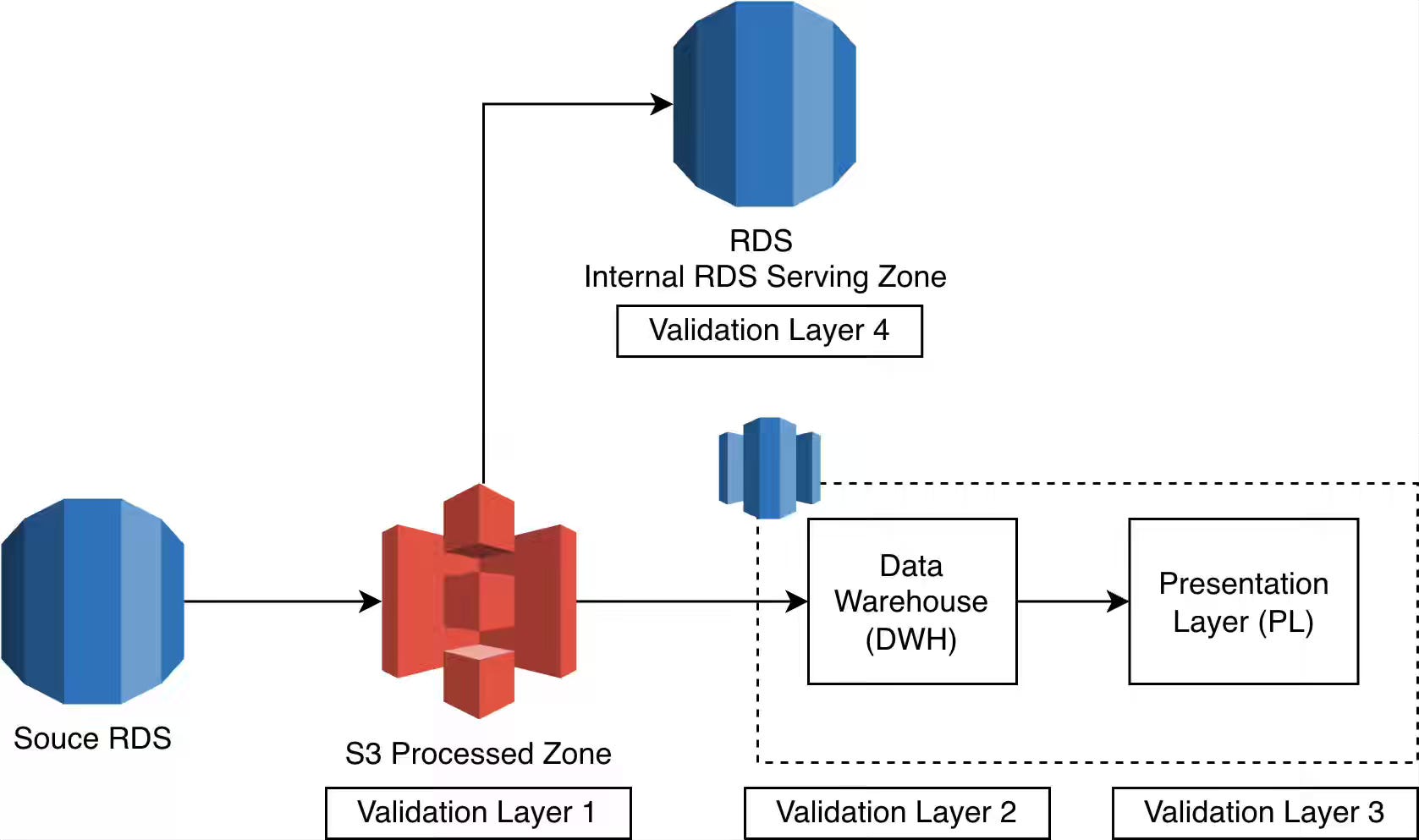
Data quality issues in healthcare analytics demand stronger guarantees than generic validation frameworks can provide. The article explains how Halodoc built a custom, configuration-driven validation pipeline with four-layered checks that combine time-bound reconciliation, AI-generated structural tests, and business-rule enforcement across the Lakehouse. By integrating LLMs into validation and surfacing failures in real time, the system reduces incidents, increases trust in analytics, and supports reliable clinical decision-making.
https://blogs.halodoc.io/halodocs-layered-data-validation-strategy/amp/
Booking.com: Beyond Prompt Engineering: How We Used Supervised Fine-Tuning for Travel Recommendations
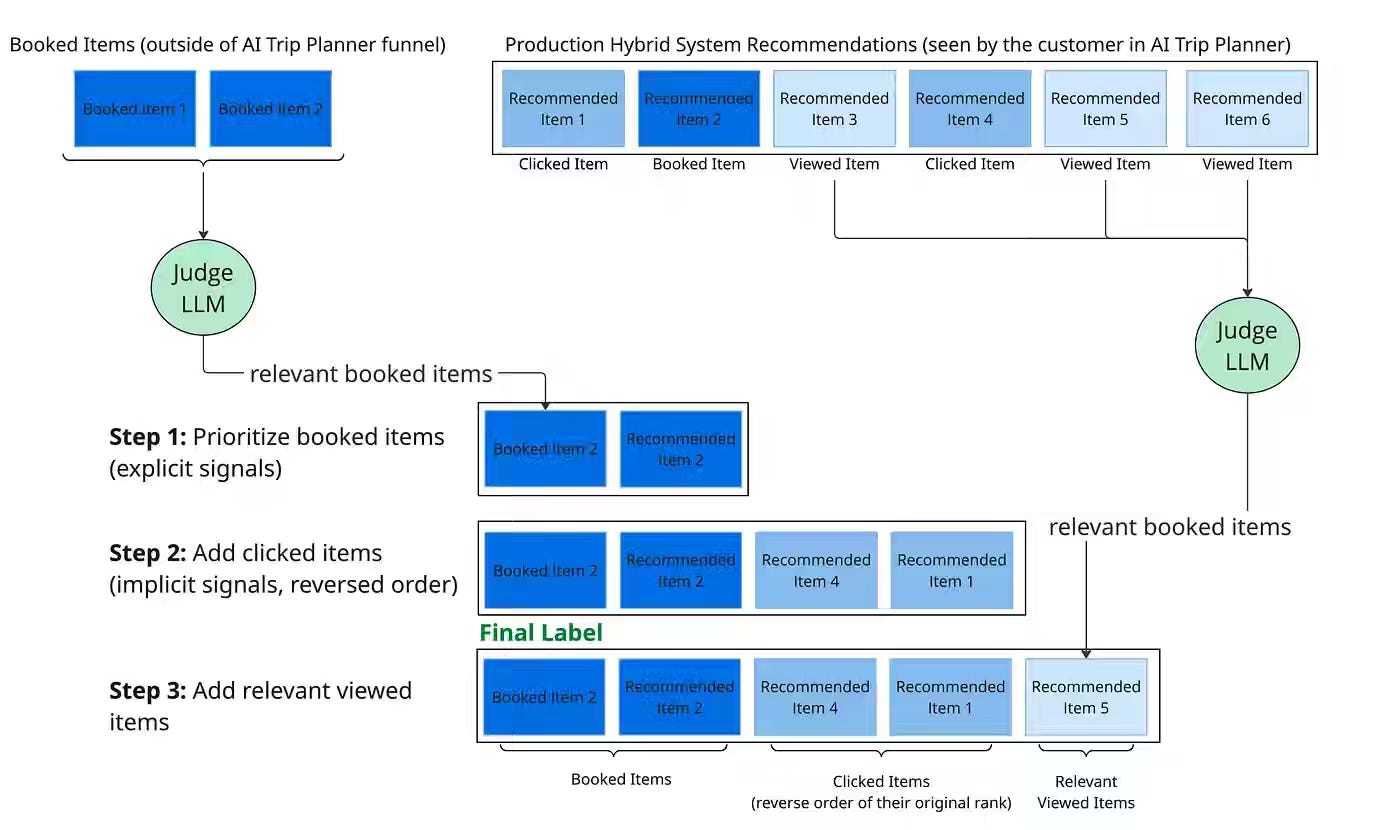
Prompt-based LLMs struggle to deliver fast, privacy-safe, and personalized travel recommendations at production scale. The article explains how Booking.com used supervised fine-tuning on an open-weight model with parameter-efficient techniques, contextual inputs, and carefully designed labels to combine conversational understanding with behavioral signals.
Pranav Mehta: Clickhouse Internals: A Deep Dive into ClickHouse Distributed Connection Pooling
ClickHouse operators may misinterpret connection-retry warnings as leaks when distributed queries encounter transient network errors. The article explains how ClickHouse reuses pooled TCP connections for distributed tables and why idle timeouts in spiky workloads produce harmless “Broken pipe” warnings.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
