Vimeo 如何实现 AI 驱动的字幕
Source: ByteByteGo
On-Demand Webinar: Designing for Failure and Speed in Agentic Workflows with FeatureOps (Sponsored)

Join Alex Casalboni (Developer Advocate @ Unleash) for a deep dive on how to design resilient AI workflows to make reversibility a foundational mechanism and release AI-generated code with confidence.
AI writes code in seconds, but reviews take hours. Don’t let this gap slow you down.
Watch our recent webinar to learn how FeatureOps helps you manage risk, contain blast radius, and maintain control over fast-moving agentic workflows.
In this webinar, you’ll learn how to:
Reduce blast radius for AI-generated changes
Separate deployment from exposure at runtime
Build reversibility into agent planning and shipping
Imagine you’re watching a video with AI-generated subtitles. The speaker is mid-sentence, clearly still talking, gesturing, making a point. But the subtitles just vanish, and there are a few seconds of blank screen. Then they reappear as if nothing happened.
This looks like a bug. But it’s a side effect of the AI being too good at translation.
Vimeo’s engineering team ran into this exact problem when they built LLM-powered subtitle translation for their platform. The translations themselves were excellent: fluent, natural, and often indistinguishable from human work. However, the product experience was broken because subtitles kept disappearing mid-playback, and the root cause turned out to be the AI’s own competence.
In this article, we will look at how the Vimeo engineering team overcame this problem and the decisions it made
Disclaimer: This post is based on publicly shared details from the Vimeo Engineering Team. Please comment if you notice any inaccuracies.
Subtitles Are a Timing Grid
A subtitle file is a sequence of timed slots. Each slot has a start time, an end time, and a piece of text. The video player reads these slots and displays text during each window. Outside that window, nothing shows. If a slot is empty, the screen goes blank for that duration.
This means subtitle translation carries an implicit contract that must be followed. If the source language has four lines, the translation also needs to produce exactly four lines. Each translated line maps to the same time slot as the original. Breaking this contract results in empty slots.
LLMs break this contract by default because they’re optimized for fluency. When an LLM encounters messy, but natural human speech (filler words, false starts, repeated phrases), it does what a good translator would do. It cleans things up and merges fragmented thoughts into a single, polished sentence.
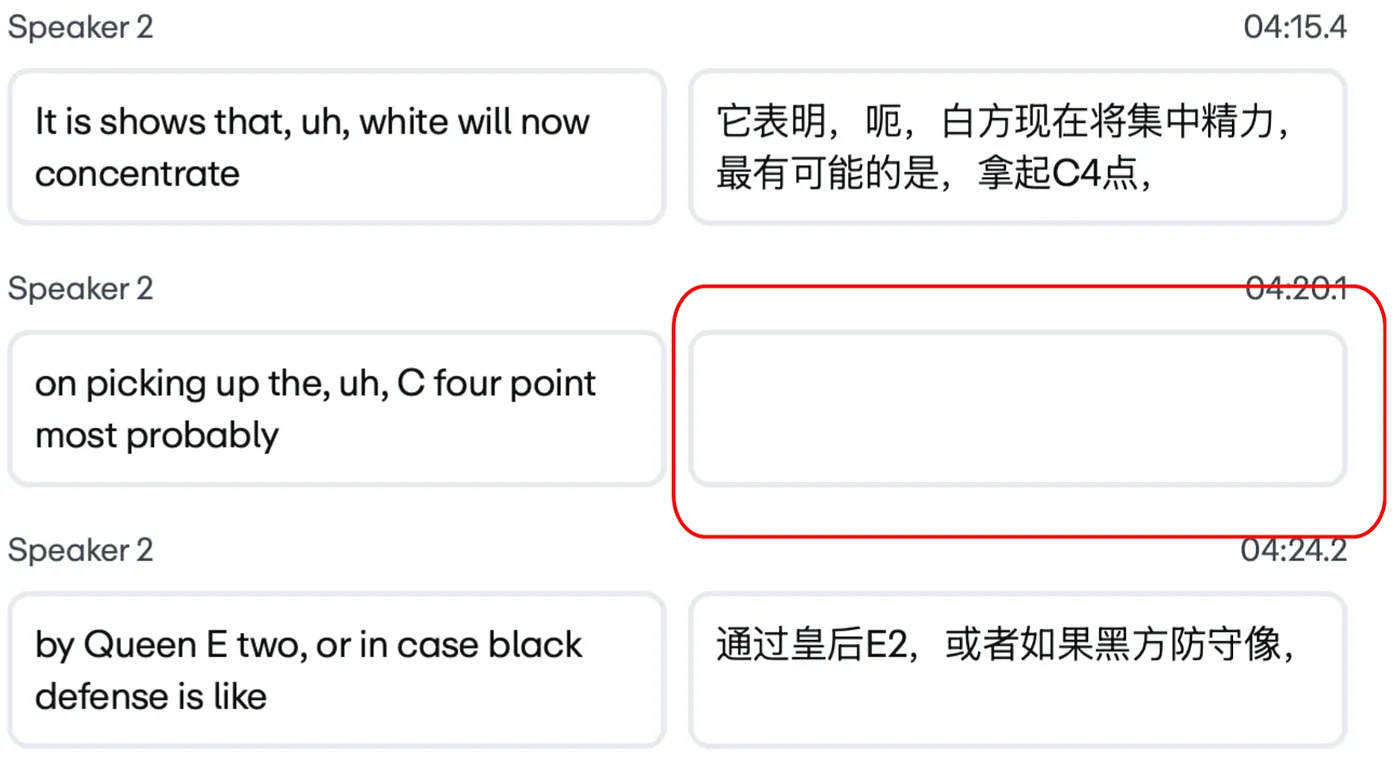
Here’s a concrete example. A speaker in a video says:
“Um, you know, I think that we’re gonna get... we’re gonna remove a lot of barriers.”
That maps to two timed subtitle slots on the video timeline. A traditional translation system handles each line separately, one-to-one. But the LLM recognizes this as a single, fragmented thought and produces one clean Japanese sentence, which is grammatically perfect and semantically accurate. But now the system has two time slots and only one line of text. The second slot goes blank, which means that the subtitles disappear while the speaker keeps talking.
Vimeo calls this the blank screen bug. And it isn’t a rare edge case. It’s the default behavior of any sufficiently capable language model translating messy human speech.
See the picture below:
If you’ve ever built anything that sends LLM output into a system expecting predictable structure (JSON schemas, form fields, database rows), you’ve probably hit a version of this same tension. The model optimizes for quality, and quality doesn’t always respect the structural contract your system depends on.
The Geometry of Language
This problem gets significantly worse when you move beyond European languages.
Different languages don’t just use different words. They organize thoughts in fundamentally different orders and densities. Vimeo’s engineering team started calling this “the geometry of language,” and it essentially signifies that the shape of a sentence changes across languages in ways that make one-to-one line mapping structurally impossible in some cases.
For example, Japanese is far more information-dense than English. Where an English speaker might speak four lines of filler (”Um, so basically,” / “what we’re trying to do” / “is, you know,” / “remove the barriers”), a typical Japanese translation consolidates all of that into a single, grammatically tight sentence.
See the example below:
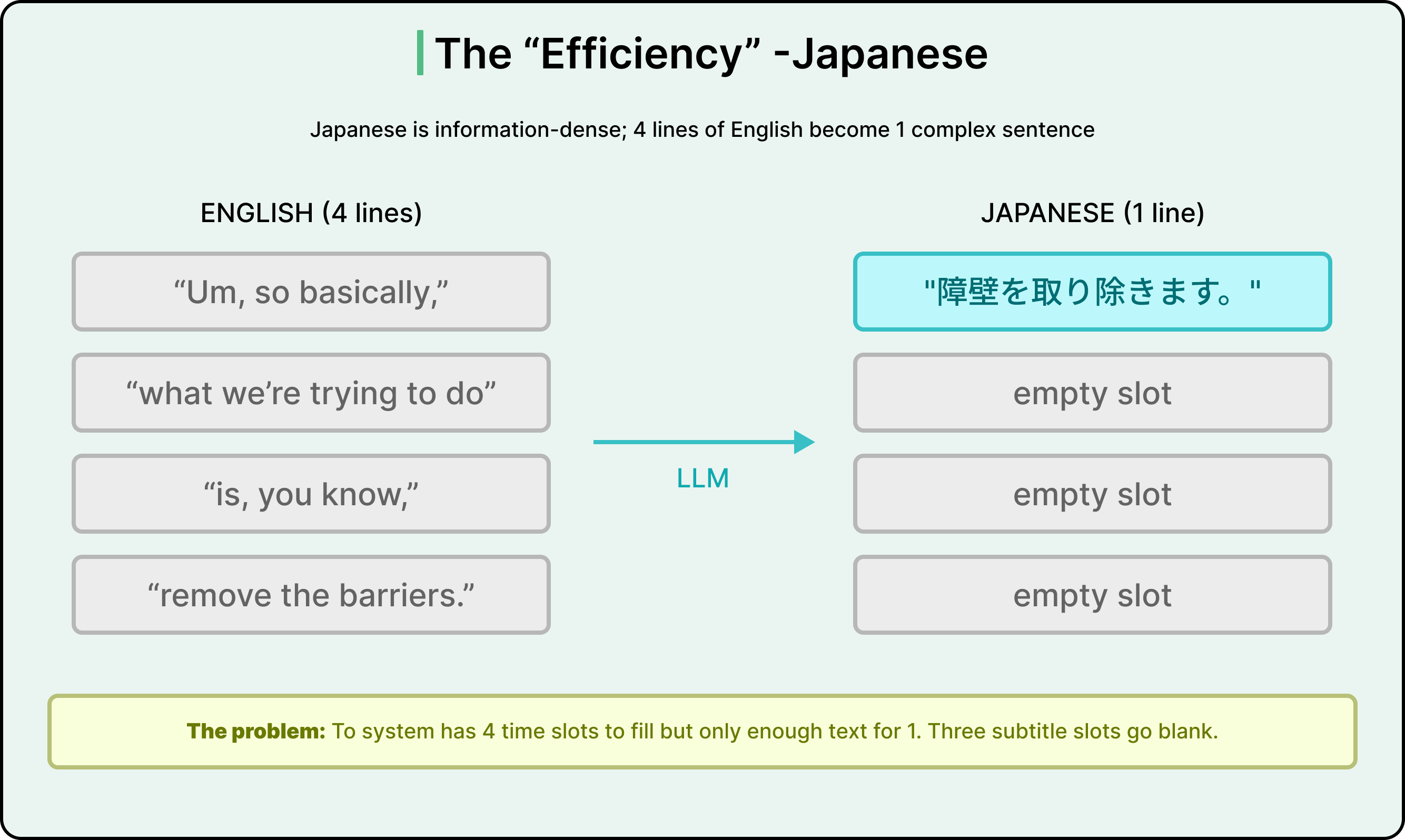
The LLM is doing the right thing linguistically. Four lines of English filler genuinely are one thought in Japanese. But the subtitle system now has four time slots and enough text for one. Three slots go blank while the speaker keeps talking.
The German language has a different problem. German places verbs at the end of clauses, creating what linguists call a “verb bracket.” If the subtitle system tries to split a German sentence at a line boundary, the first subtitle hangs grammatically incomplete, missing its verb. The LLM resists producing this because it looks like a syntax error.
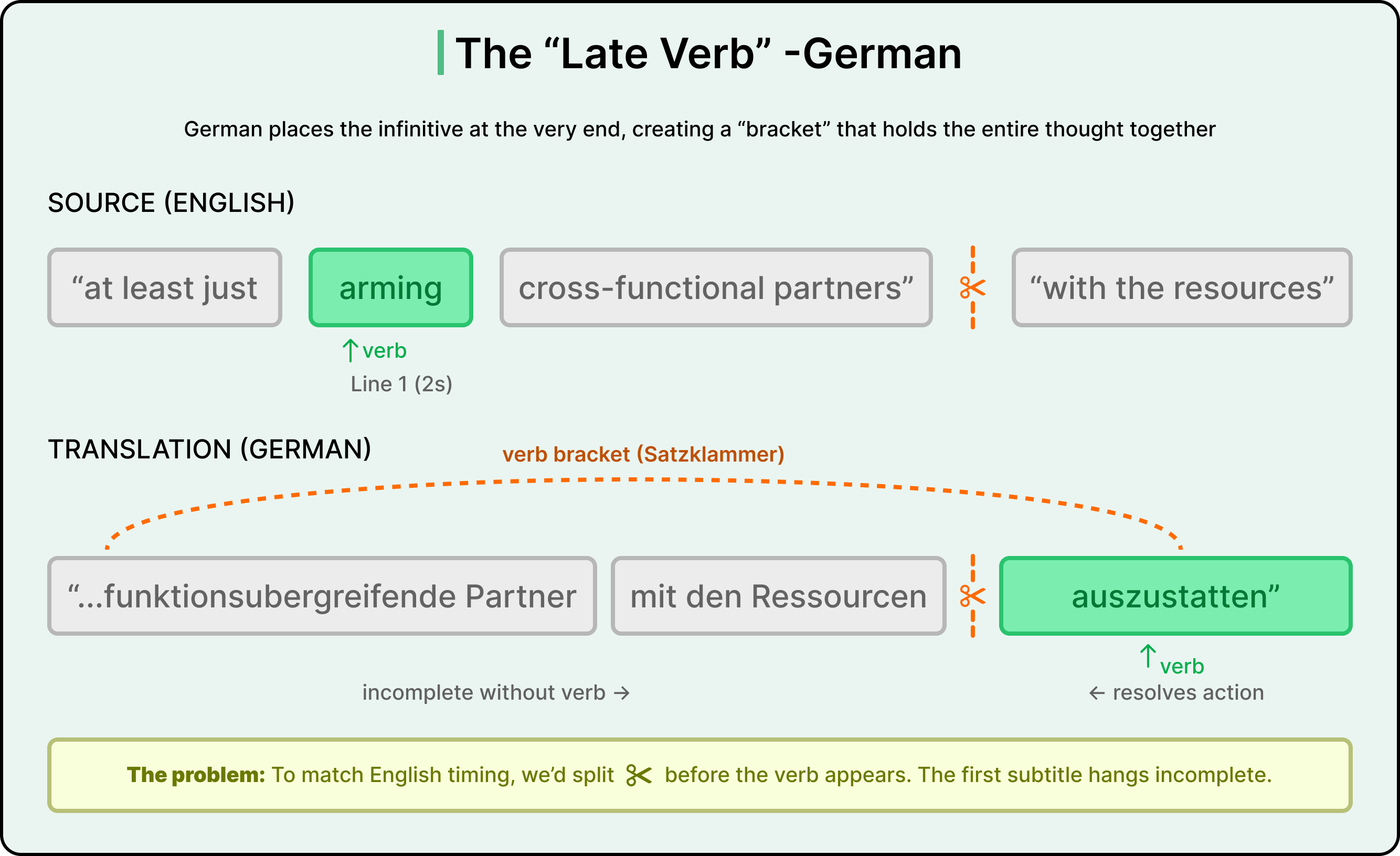
Each of these is a structurally different failure mode. The LLM is succeeding at translation while failing at structure. These are two fundamentally different jobs being crammed into a single prompt, and that realization led Vimeo to rethink its architecture.
The Split-Brain Fix
Vimeo tried the obvious approach first.
One LLM prompt that translates the text and preserves the line count. In their words, it was “a losing battle.”
The creative requirement (fluency) was constantly fighting the structural requirement (timing). Asking the model to produce natural-sounding German while also splitting it at exact line boundaries means optimizing for two competing goals at once.
Even research backs this up. A 2024 study by Tam et al. found that imposing format constraints on LLMs measurably degrades their reasoning quality. Stricter constraints often mean worse performance. In other words, you’re not just asking the model to do two things. You’re making it worse at both.
So Vimeo stopped trying to do it all in one pass. They split the pipeline into three phases.
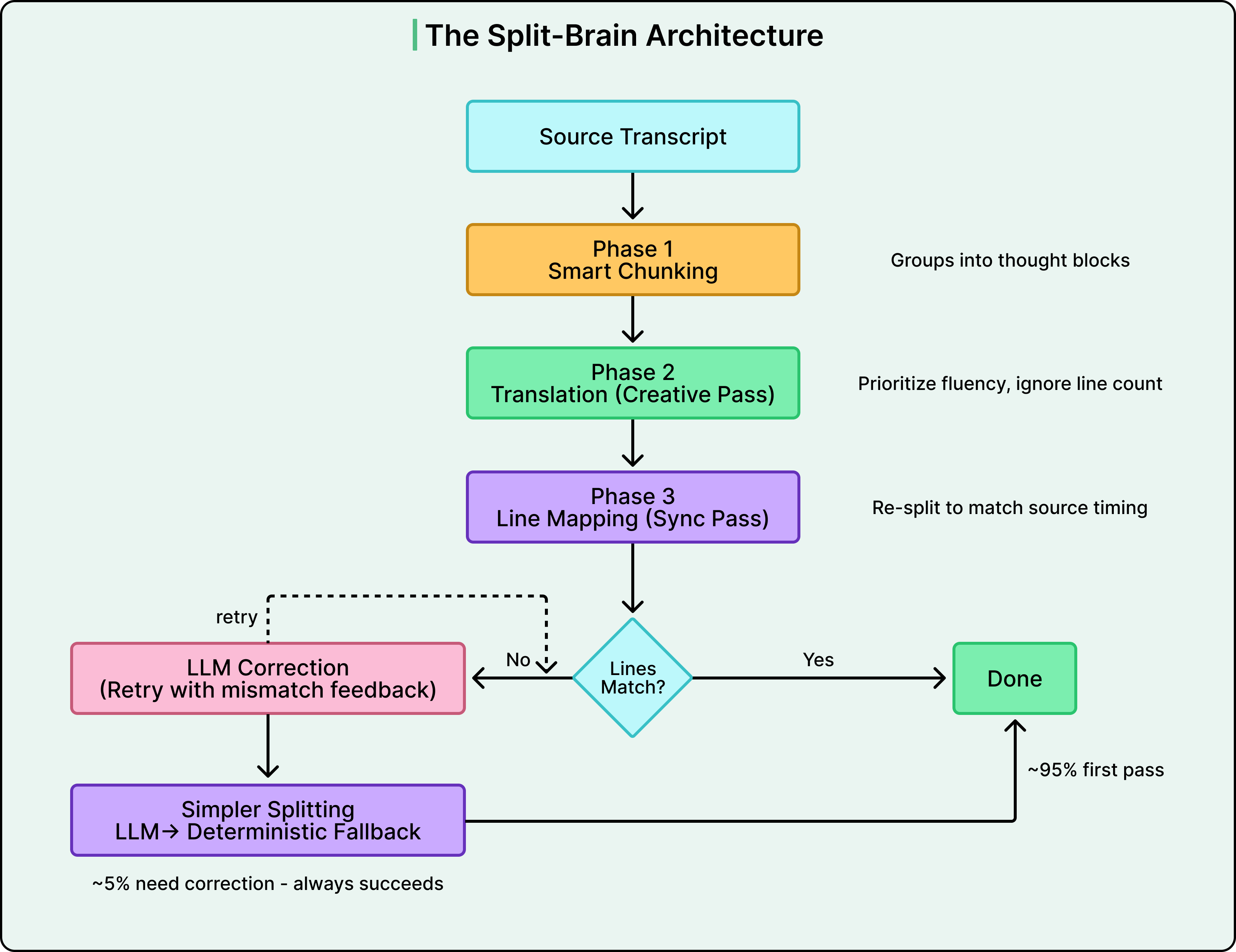
Phase 1: Smart Chunking
Before any translation happens, the system groups source lines into logical thought blocks of roughly 3-5 lines.
If we feed the LLM a single isolated line like “arming the partners,” it has zero context. It doesn’t know who is being armed or why. Feed it the entire transcript, and it loses track of where it is and starts hallucinating, meaning it generates plausible-sounding content that wasn’t in the original. The chunking algorithm scans for sentence boundaries and groups text so the LLM always sees a complete thought before translating.
Phase 2: Creative Translation.
Each chunk goes to the LLM with one instruction: translate for meaning. There is no line count enforcement and no structural constraints. The model is free to handle German verb brackets naturally, reorder Hindi syntax correctly, and compress Japanese efficiently. Linguistic quality is the only goal.
Phase 3: Line Mapping.
The fluent translated block goes into a second, separate LLM call with a completely different job. This call is purely structural.
The prompt essentially says: “Here are the original four English lines with timestamps. Here is the translated block. Break it back into four lines that match the source rhythm.” There is no concern for meaning, but only line count.
By separating these concerns, each pass gets to do its job without compromise. Phase 2 ensures the translation is grammatically sound. Phase 3 ensures the timing is respected. And on the first pass through this pipeline, roughly 95% of chunks map perfectly.
Designing for the Five Percent
Ninety-five percent is impressive. But Vimeo ships to millions of viewers across nine languages. That other five percent also matters a lot.
This is where Vimeo’s engineering philosophy gets interesting. They stopped asking “how do we make the LLM get it right the first time?” and started asking “what happens when it doesn’t?” That reframe shaped everything about how they built the production system.
When the line mapper returns a mismatch (say, one line of German when it asked for two), the system doesn’t give up. It enters a correction loop, retrying with explicit feedback about the error. The prompt tells the model what went wrong and asks it to try again. Often, the model finds a valid synonym or slightly less natural phrasing that respects the line count. This correction loop resolves about a third of failures.
If that doesn’t work, the system escalates to a simpler LLM prompt. It strips away all the semantic instructions and gives the model a bare-bones task: “Here’s one block of text. Split it into exactly N lines.”
And if the LLM still can’t produce the right count, Vimeo stops asking models entirely. A rule-based algorithm takes over. Empty lines get filled with the last valid content. Too few lines get padded by duplicating text. Too many lines get truncated. The output in these edge cases is functional rather than perfect. You might see the same phrase repeated across a couple of subtitle slots. But every time slot gets filled, and the viewer never sees a blank screen.
This graduated fallback is what separates a production system from a demo. Vimeo’s data showed that the correction loop resolves about 32% of the failures that make it past the first pass. The rule-based splitter catches everything else. The result is 100% of chunks reach the user in a valid state.
Conclusion
This architecture works. But it carries real costs.
The multi-pass approach adds roughly 4-8% more processing time and 6-10% more token cost compared to a single-call translation. Vimeo argues this tradeoff pays for itself by eliminating around 20 hours of manual QA per 1,000 videos. At their scale, the math works clearly. At a smaller scale, it might not.
There’s also an uncomfortable quality gap across languages. The system ensures every language gets functional subtitles, but speakers of structurally different languages hit the fallback chain far more often than Spanish or Italian speakers. That means more repeated phrases, more slightly awkward line splits. The system guarantees no blank screens, but it doesn’t guarantee equal quality.
And there’s a genuine product question embedded in the rule-based fallback. When the system repeats a phrase across two subtitle slots to avoid a blank screen, is that actually a better viewer experience? Vimeo decided it is. That’s a reasonable product call, but it’s worth recognizing as a decision, not a technical inevitability.
The broader value of Vimeo’s experience reaches well beyond video subtitles. If you’re building AI into any product with structural constraints, their journey points to three principles that can be understood:
First, separate the creative work from the structural work. Asking one LLM call to be both brilliant and obedient means optimizing for competing goals, and research suggests that makes it worse at both.
Second, build your fallback chain before you build your happy path. The question isn’t how to prevent failures. It’s what your system does when they happen.
Third, accept that smarter models need smarter infrastructure around them. A simple word-for-word translator would never break subtitle sync. Intelligence is what creates the engineering challenge. Vimeo calls this the “infrastructure tax of intelligence,” and it’s a cost worth understanding before you build.
References: