数据工程周报 #261
Source: Data Eng Weekly

How to Orchestrate Databricks Across Multiple Workspaces
As Databricks deployments scale, a familiar pattern emerges: multiple workspaces, multiple teams, and no reliable way to manage the dependencies between them.
In this hands-on deep dive, we'll show you how to build a cross-workspace control plane using Dagster on top of your existing Databricks environment. Demo-heavy and practitioner-focused, you'll leave with working patterns you can apply to your own platform the same day.
Editor’s Note: Introducing Data Engineering After AI Podcast Series
Lately, I’ve been thinking a lot about the intersection of data architecture and AI. To dig deeper into this, I’m launching a new podcast series called Data Engineering After AI.
I’m looking for guests who are in the trenches. If you have strong opinions on where the industry is heading, or if you are actively building solutions in this space (either in-house or as a product), let’s talk.
Please note: my goal is to foster an authentic discussion about how AI is reshaping data engineering from the ground up. This isn’t a space for promotional product pitches, and I want to keep the conversation strictly focused on the technology, the challenges, and the architectural shifts.
If you are passionate about the future of our field and want to share your insights, DM me on LinkedIn.
Joseph M. Hellerstein: AI and the Mixed-Consistency Future
In my recent article, ETL is dead, I projected that the data modeling techniques that got us here may not be sufficient for the AI era. The consistency model is one of the biggest gaps in the emerging file-based system design around the AI Agent. We have seen this shift from the Hadoop file system to the Lakehouse model. The author suggests that we may be entering the Mixed-Consistency future.
https://jhellerstein.github.io/blog/ai-mixed-consistency/
Milan Mosny: Ontology, Taxonomy, Data Model, Context Graph & Friends
Context Engineering is the hot topic in the industry. I found the author did an excellent recap on ontology, taxonomy, data model & context graph. As the famous saying goes, it is all data engineering.
https://medium.com/response42/ontology-taxonomy-data-model-context-graph-friends-56a605e14355
Jason Cui & Jennifer Li: Your Data Agents Need Context
Contextual grounding—standardized terminology, data lineage, operational semantics—determines whether natural language agents answer analytics questions reliably. The authors propose a “Context Layer” combining LLM-powered metadata construction with human refinement to map business knowledge onto warehouse schemas. Organizations adopting context-aware agent architectures unlock self-serve analytics without brittleness, enabling agents to reason consistently across disparate schemas.
https://www.a16z.news/p/your-data-agents-need-context
Sponsored: The AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Robin Moffatt: Claude Code isn’t going to replace data engineers (yet)
We see some degree of success with the Claude Code in software engineering. Is it ready for the prime data engineering? The author noted the gap in trust & accuracy, silent data loss, non-determinism, technical flaws, and maintenance. There is a data engineering gap in building an efficient sandbox environment to bridge it, which is a must for brownfield projects.
https://rmoff.net/2026/03/11/claude-code-isnt-going-to-replace-data-engineers-yet/
Snap: Agent Format: A Declarative Standard for AI Agents
Speed and Correctness in execution always have their own trade-off. Snap writes about how different teams adopted different AI frameworks to move fast and focus on standard interface design to make everything work together. I believe as long as the pendulum swings between speed and efficiency, the software engineering is safe. We will always build the next best abstraction.
https://eng.snap.com/agent-format
LinkedIn: Engineering the next generation of LinkedIn’s Feed
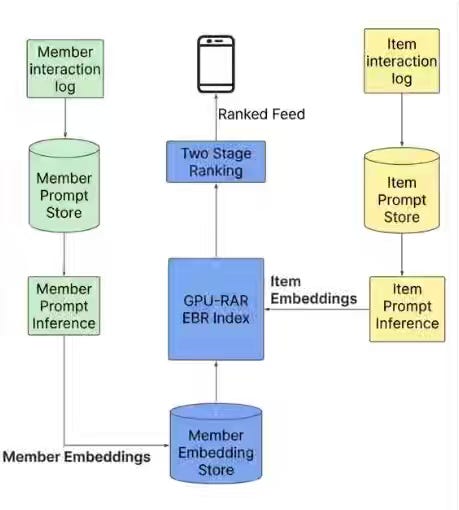
Feed personalization at a massive scale requires unifying disparate retrieval signals into semantic representations while maintaining sub-second latency across billions of users. LinkedIn's architecture consolidates keyword matching, collaborative filtering, and engagement signals into a dual-encoder LLM retrieval paired with a Generative Recommender transformer that sequences 1,000+ historical interactions to capture professional trajectories. Custom infrastructure—Flash Attention variants, GPU-optimized data loaders, decoupled nearline pipelines—enables semantic ranking at sub-second latency for 1.3 billion members while reducing training memory by 37%.
https://www.linkedin.com/blog/engineering/feed/engineering-the-next-generation-of-linkedins-feed
Spotify: Inside the Archive: The Tech Behind Your 2025 Wrapped Highlights
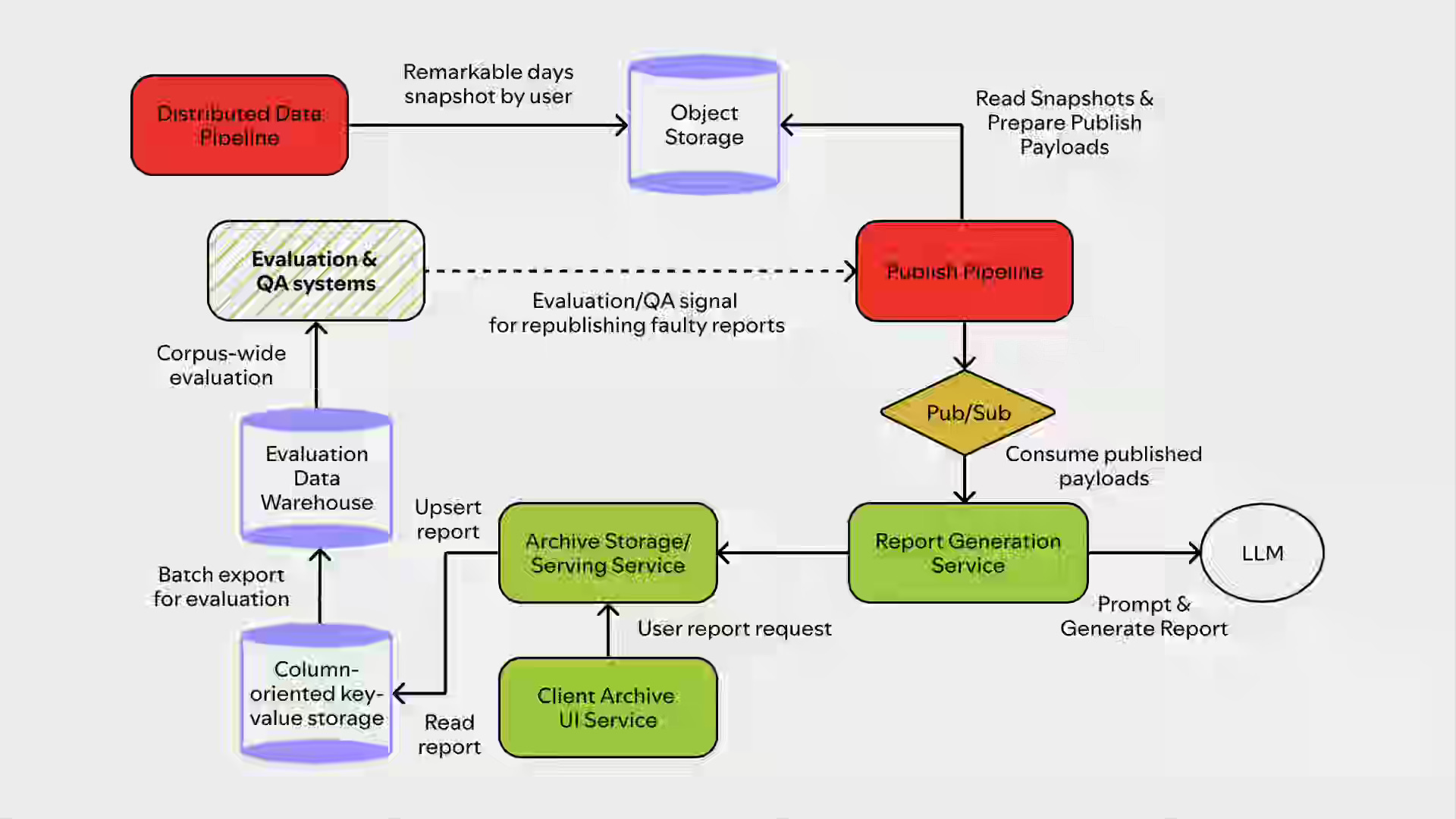
Generating personalized narratives at a billion-scale requires balancing creative consistency, latency constraints, and data fidelity without requiring human review. Spotify's Wrapped Archive distills frontier LLM outputs into smaller production models via DPO, grounds narratives in heuristic-ranked "remarkable days" from distributed pipelines, and uses layered prompts to enforce tone while preventing hallucinations. Column-oriented storage with per-day qualifiers, pre-scaled compute, and automated Judge-model sampling of 165,000 reports enables 1.4 billion unique narratives at launch latency while catching systemic failures such as timezone bugs.
https://engineering.atspotify.com/2026/3/inside-the-archive-2025-wrapped
LinkedIn: Driving data enhancement & recruitment success with LinkedIn’s unified integrations
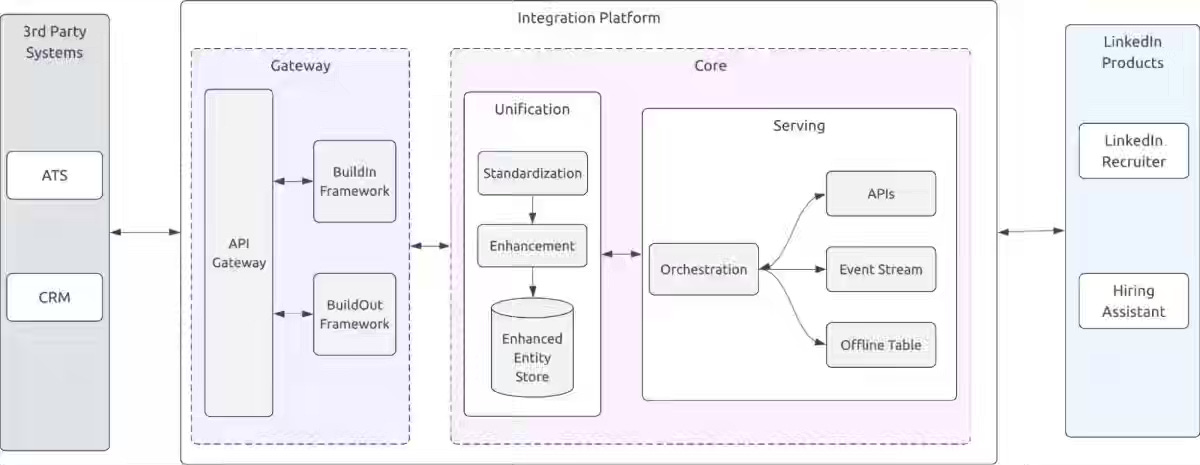
Recruitment data fragmentation—disparate ATS schemas, semantic conflicts, and partner integration overhead—blocks AI agents from reliably reasoning across hiring pipelines. LinkedIn's unified platform standardizes partner data into canonical schemas via hybrid push/pull models (BuildIn for speed, BuildOut with Temporal orchestration for reliability), assigns stable Integration IDs to decouple identity, and reconciles multi-source conflicts into single-truth serving layers. The system cut onboarding from 12 months to 4, expanded job field coverage 1.8x, and dropped resume gaps below 10%, enabling agents to reason and act consistently across enterprise hiring systems.
Uber: Transforming Ads Personalization with Sequential Modeling and Hetero-MMoE at Uber
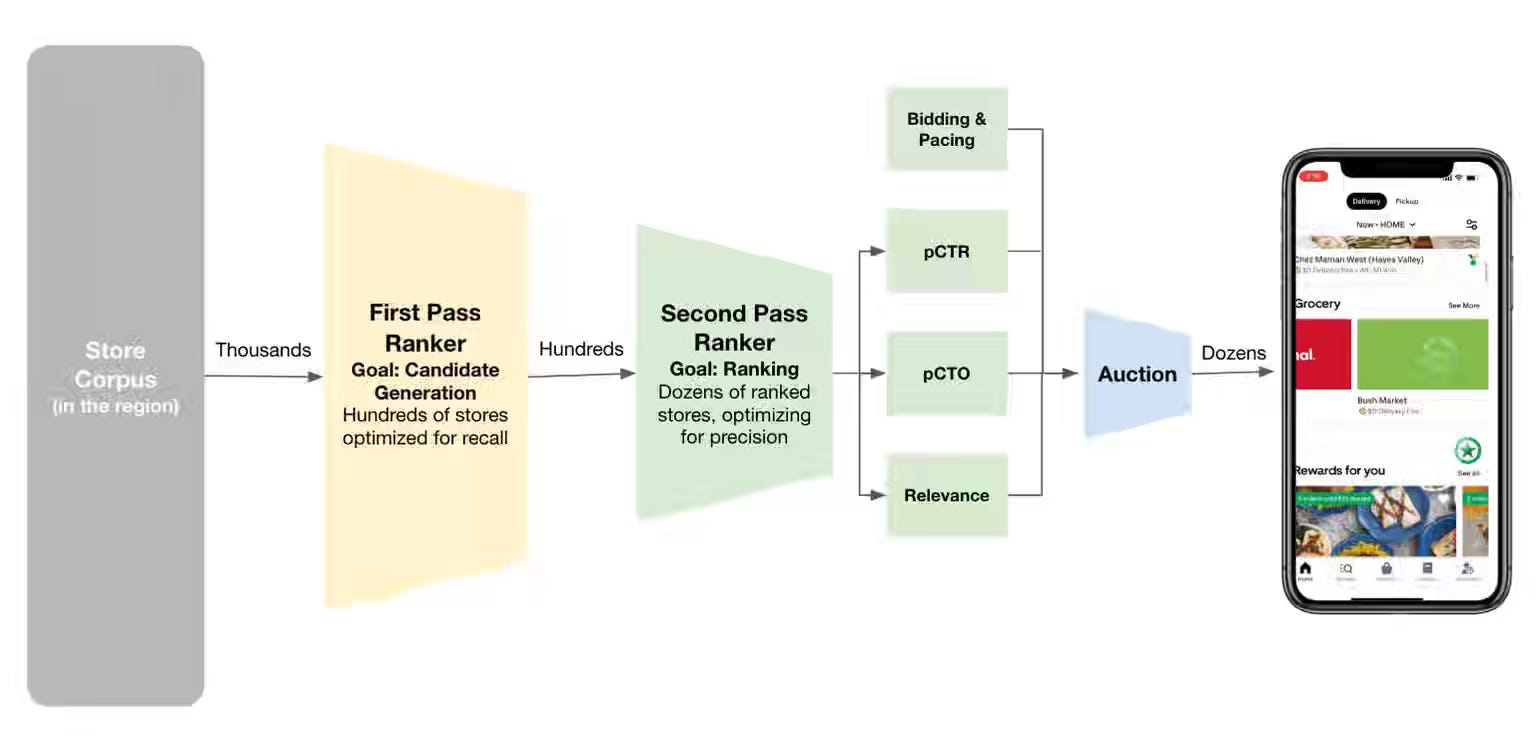
Ads ranking at scale requires capturing sequential user intent over long behavioral histories while simultaneously optimizing competing objectives such as clicks and conversions. Uber's system pairs target-aware transformers with Multi-Head Latent Attention (reducing sequence complexity from O(N²) to O(N×L)) to compress engagement histories, then routes the compressed signals through Hetero-MMoE—blending DCN and CIN experts to capture low- to high-order feature interactions across multimodal inputs. Online experiments yielded +0.93% AUC on predicted CTR and +0.66% AUC on predicted click-to-order, validating sequential modeling at the ranking scale.
https://www.uber.com/en-EG/blog/transforming-ads-personalization/
Databricks: LogSentinel: How Databricks uses Databricks for LLM-Powered PII Detection and Governance
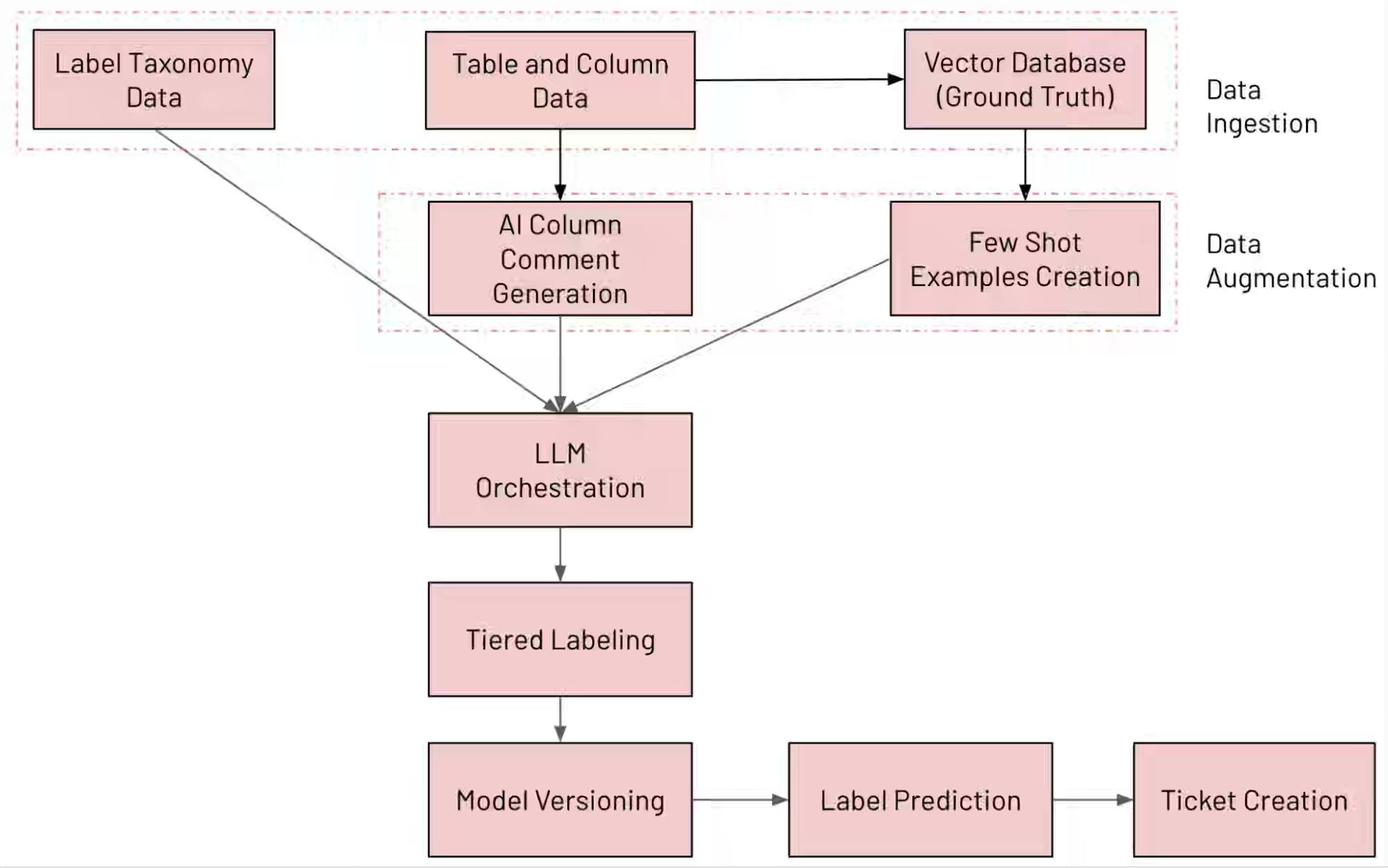
PII discovery and compliance monitoring at a data warehouse scale requires automating label classification across schema evolution without manual audit cycles. Databricks’ LogSentinel orchestrates multiple LLM “experts” in parallel—augmented with Vector Search context and AI-generated column comments—to classify data across 100+ granular, hierarchical, and residency labels, selecting predictions by confidence voting. The system achieves 92% precision and 95% recall while reducing manual review cycles from weeks to hours, enabling real-time governance as schemas drift.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
