Roblox 如何使用 AI 在 100 毫秒内翻译 16 种语言
Source: ByteByteGo
OpenClaw You Can Trust (Sponsored)

When your AI agent holds your API keys, reads your email, and runs shell commands, security isn’t optional.
KiloClaw is a fully managed OpenClaw: a one-click deploy that gives you a 24/7 AI agent, without buying a Mac Mini.
Every instance runs in a dedicated Firecracker micro-VM, not a shared container, with five independent isolation layers protecting your data. An independent security assessment found zero cross-tenant vulnerabilities (read the full white paper).
Built on the same infrastructure serving 1.5M+ Kilo Code developers, with access to 500+ AI models through Kilo Gateway.
Translating between 16 languages means supporting 256 possible pairs, such as Korean to English, French to Thai, Portuguese to Japanese, and so on. One solution is to build a separate model for each pair. However, Roblox decided to build just one.
Roblox is a global platform where more than 70 million people play, create, and socialize every day across more than 15 million active experiences. Users span 180 countries and communicate constantly through in-experience text chat. And a single unified model now handles real-time chat translation across all of those users, at roughly 100 milliseconds per translation and over 5,000 chats per second.
However, Roblox’s real engineering challenge wasn’t building a model that could translate. It was building a system that could translate at the speed of a conversation without breaking the user experience. In this article, we will look at what Roblox built and the trade-offs they made.
Disclaimer: This post is based on publicly shared details from the Roblox Engineering Team. Please comment if you notice any inaccuracies.
One Model Versus Many
Building a separate model for every language pair is the obvious starting point. One model for English to Korean, another for Korean to French, another for French to Thai, and so on.
With 16 languages, that’s 16 times 16, or 256 individual models. Each one needs its own training data, its own infrastructure, its own maintenance. And when Roblox adds a 17th language, they don’t need a new model. They need 32. The approach grows quadratically, and it collapses under its own weight long before you reach production.
Roblox went a different direction.
They built a single, unified transformer-based translation model that handles all 256 language directions. The key to making this work is an architecture called Mixture of Experts, or MoE. Instead of every translation request passing through every parameter in the model, a routing mechanism activates only a subset of specialized “expert” subnetworks depending on the input.
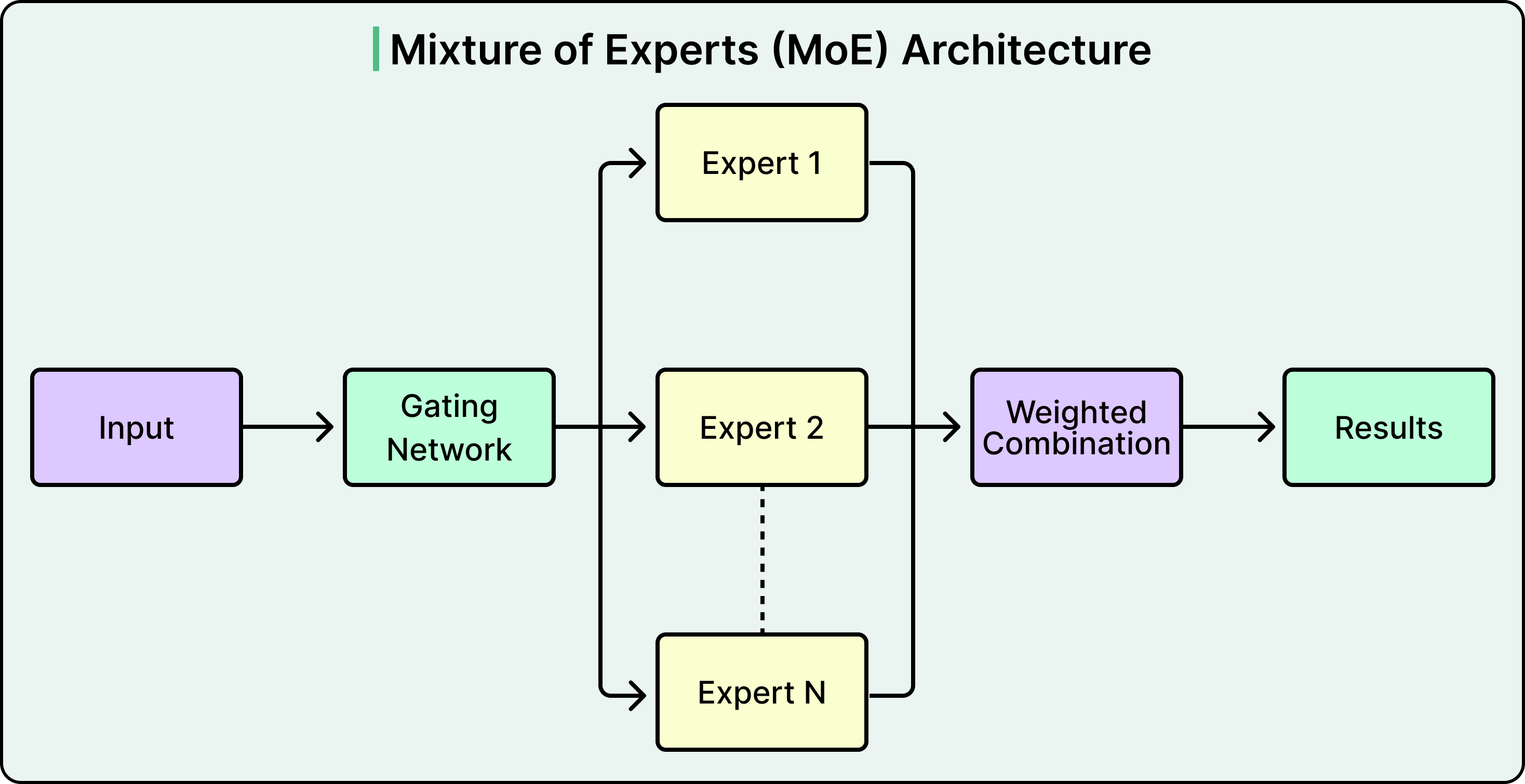
Different experts specialize in groups of similar languages. Given a source sentence and a target language, the system activates the relevant expert (or combination of experts) to generate the translation. Think of it as a team of specialist translators sitting behind a single reception desk. A request comes in, the routing layer sends it to the right specialist, and only that specialist does the work. The full team has broad expertise, but any single translation only activates a fraction of it.
This unified approach creates some great benefits. When all languages are trained together, similar languages actually help each other. For example, Spanish and Portuguese share enough structure that training them in the same model improves translation quality for both. The model also learns enough about each language’s patterns that it can auto-detect the source language, even when the language setting is wrong or missing. It can even handle mixed-language input, where someone types in two languages within the same message, and still produce a reasonable translation into the target language.
However, there’s a cost to consolidation. One model now carries the weight of all 256 directions. To handle that diversity with acceptable quality, Roblox’s model ended up with roughly 1 billion parameters. Running inference through a model that large is too slow and too expensive for real-time chat at scale. The architectural problem was solved, but the serving problem was just getting started.
Unblocked: Context that saves you time and tokens (Sponsored)

Stop babysitting your coding agents. Unblocked gives them the organizational knowledge to generate mergeable code without the back and forth. It pulls context from across your engineering stack, resolves conflicts, and cuts the rework cycle by delivering only what agents need for the task at hand.
Making a Billion Parameters Fast Enough for a Conversation
A 1-billion-parameter model produces good translations. It does not produce them fast enough for two people having a real-time conversation.
At 5,000+ chats per second, with a latency ceiling of roughly 100 milliseconds, Roblox needed to close a significant gap to make things production-ready. They did it with two moves. First, they made the model smaller. Then, they wrapped it in infrastructure that squeezes out every remaining millisecond.
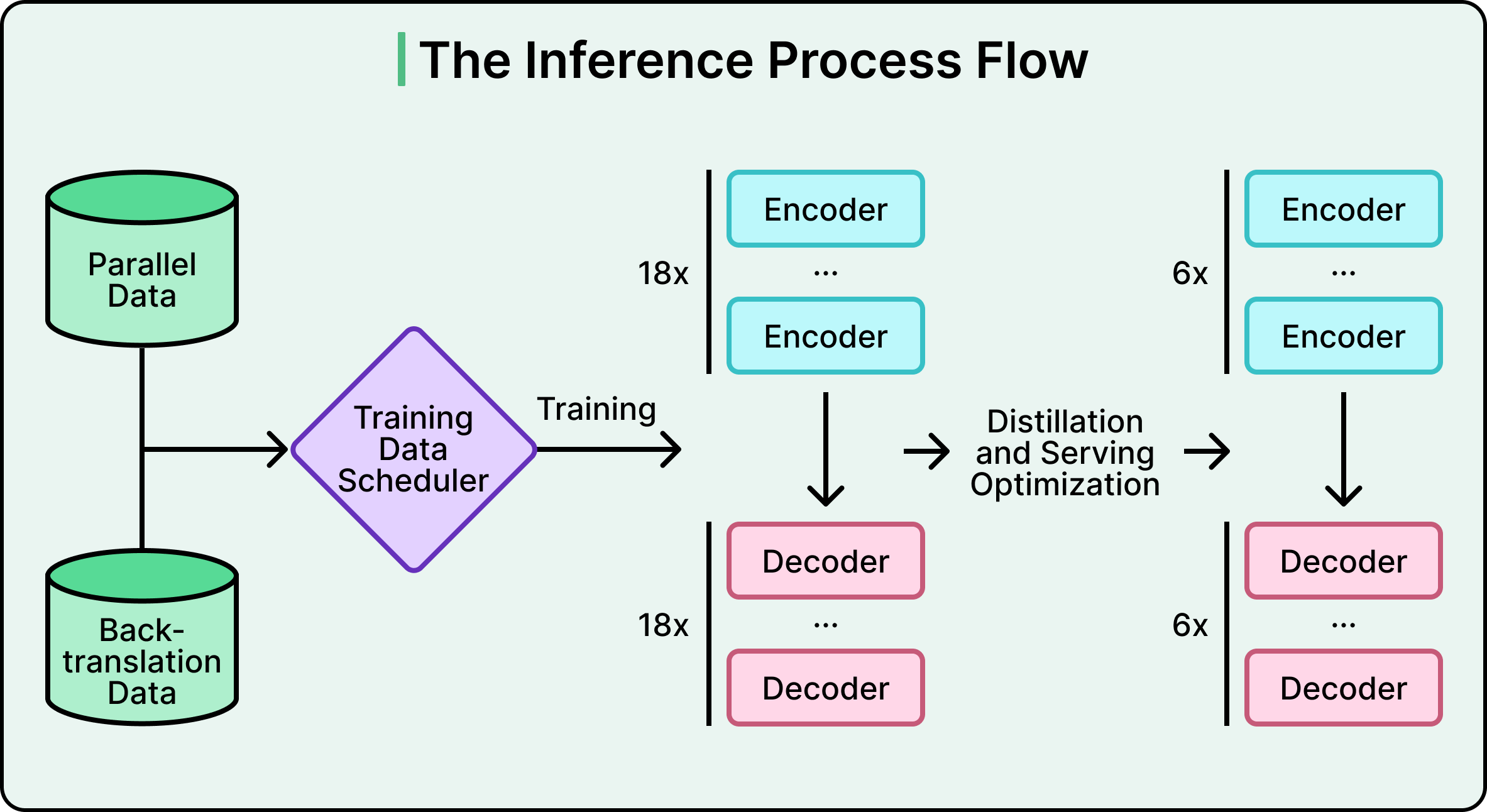
Roblox used a technique called knowledge distillation, sometimes described as a teacher-student approach. The idea is straightforward. You train a large, high-quality model first (the teacher). Then you train a smaller model (the student) to mimic the teacher’s outputs. The key detail is what the student actually learns. It doesn’t just learn the teacher’s final answers. It learns the teacher’s probability distributions, in other words, the teacher’s confidence levels across all possible translations for a given input.
Through this process, Roblox compressed the model from roughly 1 billion parameters to fewer than 650 million. Alongside distillation, they also applied quantization (reducing the numerical precision of model weights) and model compilation (optimizing the computation graph for specific hardware). These are additional layers of compression stacked on top of distillation.
However, the serving infrastructure is half the story. Even a distilled model doesn’t hit 100ms on its own at this scale. The model is just one component in a longer pipeline, and most of the latency optimization happens outside the model itself.
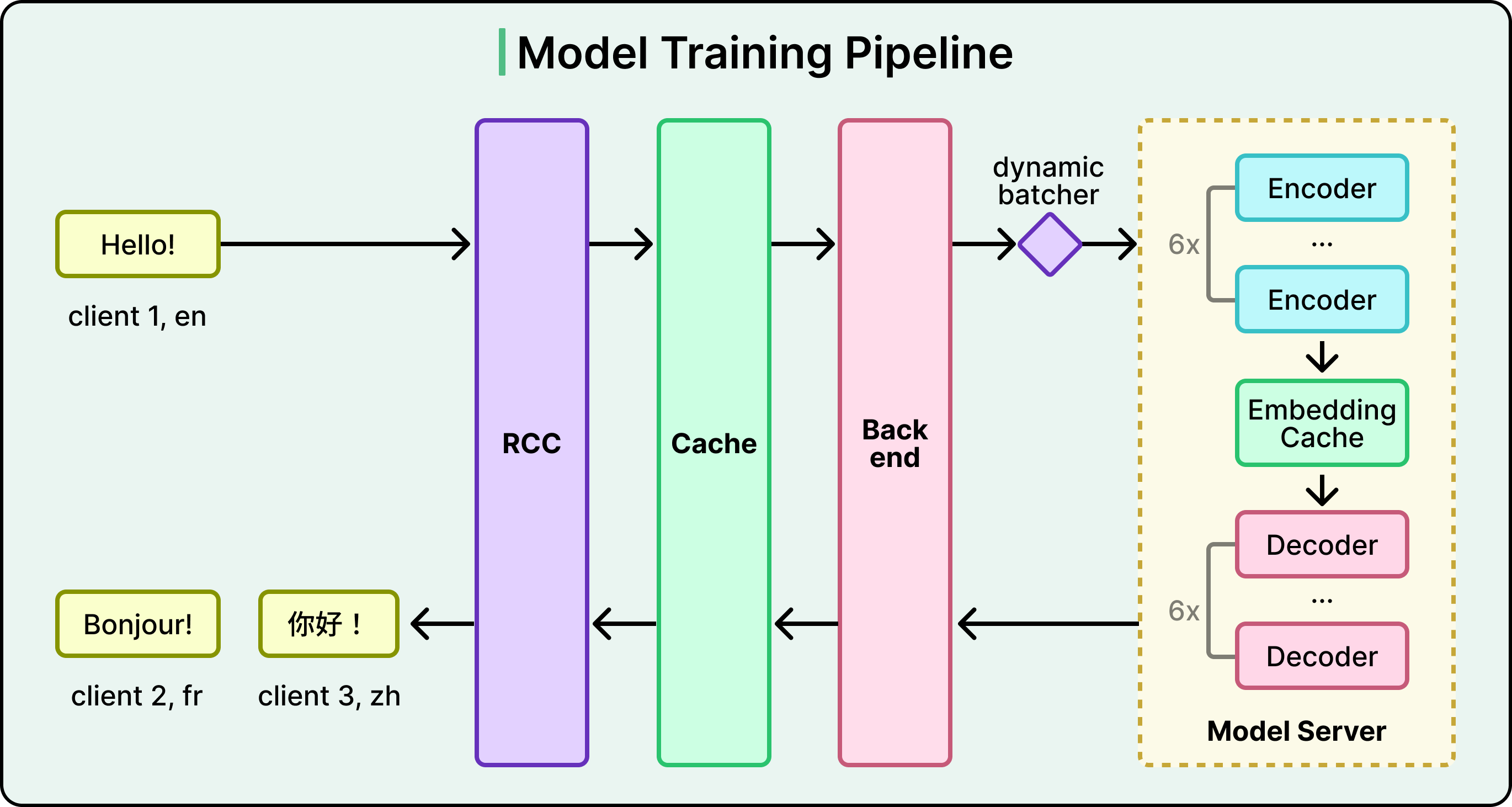
When a chat message needs translation, it first passes through RCC (Roblox’s backend service). Before the model is ever involved, the system checks a translation cache. If this exact source-text-to-target-language translation has been done before, the cached result is returned immediately, and no model inference is needed.
If the cache misses, the request goes to the backend, where a dynamic batcher groups multiple translation requests together. Batching is critical because GPUs are far more efficient at processing many inputs at once than handling them one at a time. The batched requests then flow through the model’s encoder stack, which converts the source text into a numerical representation.
Here’s where a second, different cache comes in. Roblox added an embedding cache between the encoder and decoder. This matters for a specific scenario that happens constantly on the platform. Imagine a Korean speaker sends a message on a server with English, German, and French speakers. That single Korean message needs three separate translations. Without the embedding cache, the encoder would process the same Korean message three times. With it, the encoding happens once, the intermediate representation is cached, and the decoder generates all three translations from that single encoding. At the scale of Roblox’s chat traffic, this optimization is significant.
Finally, the decoded translation passes through Roblox’s trust and safety systems, the same scrutiny applied to all text on the platform, to catch anything that violates their policies. The translated message and the original are both sent to the recipient’s device, allowing users to toggle between the translation and the sender’s actual words.
Measuring Quality
A translation model is only as good as two things. The data it was trained on, and your ability to measure whether it’s working. For 256 language directions at Roblox’s scale, both of these are hard problems. And Roblox had to build custom solutions for each.
Standard translation quality metrics work by comparing the model’s output against a “correct” human translation, called a reference. But producing reference translations for all 256 language directions, across the volume and variety of Roblox chat messages, is impossible. You’d need human translators producing ground truth for every combination, continuously. Roblox solved this by building its own quality estimation model that scores translations using only the source text and the machine translation output. No reference translation required.
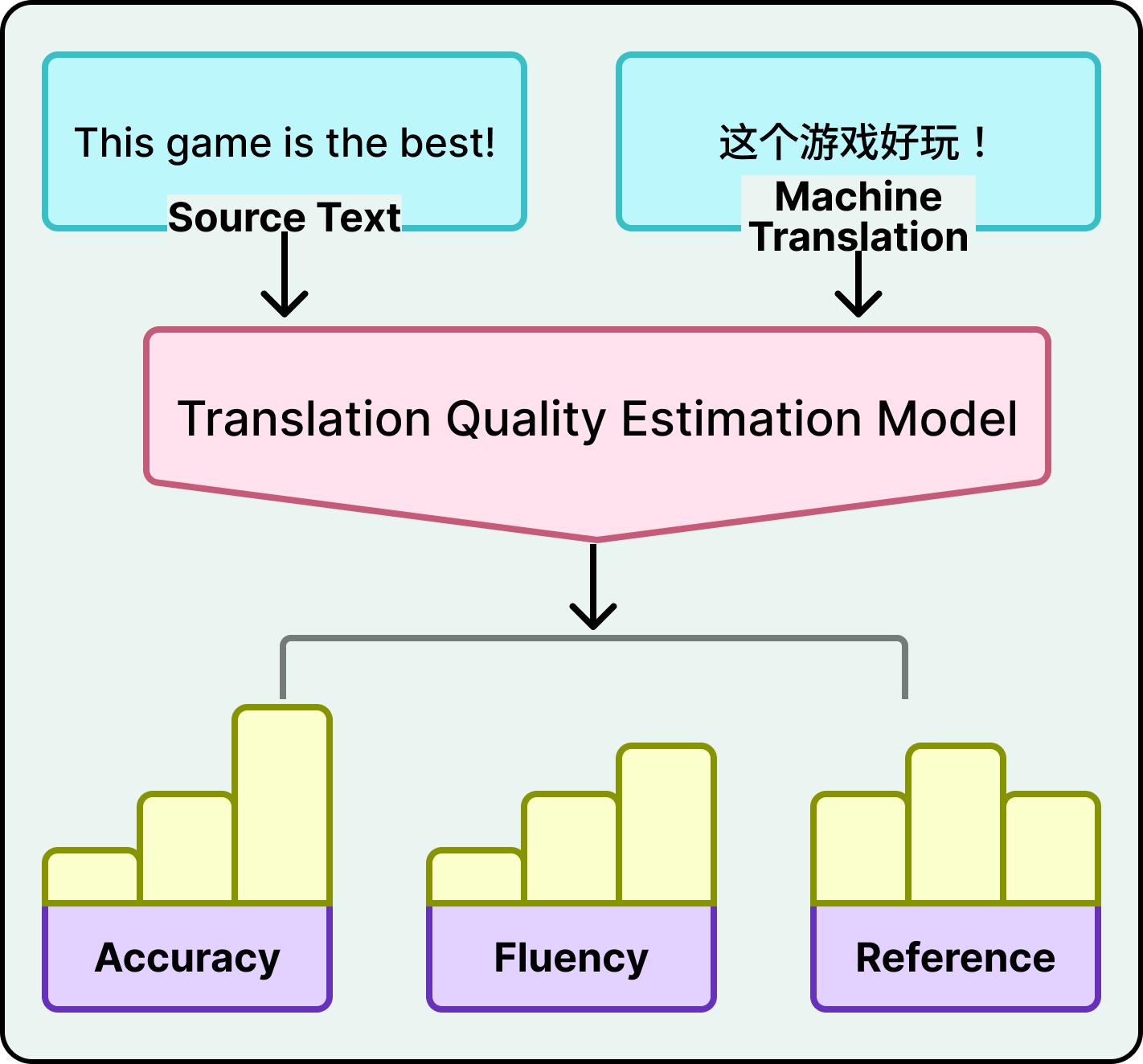
This quality model evaluates the translations along multiple dimensions.
It checks accuracy (are there additions, omissions, or mistranslations?), fluency (grammar, spelling, punctuation), and reference consistency (does the translation make sense in context with the rest of the conversation?).
Errors are classified by severity into critical, major, and minor categories. The model operates at word-level granularity, not just sentence-level. It doesn’t just flag a translation as “bad.” It pinpoints which words are wrong and how severely.
To build this, Roblox trained an ML model on human-labeled error types and scores, then fine-tuned a multilingual language model to predict these word-level errors and compute scores across their multidimensional criteria.
Common language pairs like English-Spanish have abundant parallel training data. Billions of translated sentence pairs exist on the web. However, there are also rare pairs like French-Thai. It’s difficult to train a good translator between two languages if you don’t have examples of translations between them.
Roblox addressed this with iterative back-translation. Take a French text, translate it into Thai using the current model, then translate that Thai text back into French. Compare the round-trip result to the original French. If it matches closely, the intermediate French-Thai pair is probably a good synthetic training example.
The critical word to note here is “iterative.” Roblox didn’t do this once. They repeated the process across multiple rounds, using a mix of this synthetic back-translated data and human-labeled supervised data to progressively expand the training set. The ratio between synthetic and real data matters. Too much synthetic data degrades quality because the model starts learning from its own mistakes.
General translation data doesn’t include words like “obby” (a Roblox obstacle course) or platform-specific slang and abbreviations. Roblox brought in human evaluators to translate popular and trending terms for each of the 16 languages, then fed those translations into the training data. This is an ongoing process because slang evolves faster than any model retraining.
Conclusion
Roblox’s unified translation model came with real costs, and understanding those costs matters as much as understanding the architecture.
Quality vs. latency is a permanent tension. The distilled student model is inherently less accurate than the teacher. Every time Roblox improves the teacher, they face the question of whether those gains survive compression. And 100 milliseconds is a hard ceiling that limits how large and accurate the serving model can get.
Low-resource pairs are still the weak link. Back-translation helps, but French-to-Thai will never be as good as English-to-Spanish. The model can handle mixed-language input, but accuracy drops. Unified doesn’t mean uniform quality.
The maintenance burden is real. Building a custom translation model means owning the entire stack. Training, evaluation, serving, slang updates, safety integration, all of it. Using a commercial translation API means someone else handles that complexity. Roblox’s choice made sense because they needed domain-specific accuracy (their model outperforms commercial APIs on Roblox content, by their own metrics) and extreme latency at massive scale. Most companies should use off-the-shelf translation and spend their engineering effort elsewhere.
The reference-free quality estimation model, while clever, has an inherent limitation. It could have systematic biases that overlap with the translation model’s own weaknesses. It’s a pragmatic solution, not a perfect one.
References: